Jun 14, 2026
The FMIN function at Netlib is based on Richard Brent's classic localmin algorithm from [1].
The method uses a combination of golden section search and successive parabolic interpolation to compute the minimum of a 1D function without the necessity of evaluating any derivatives. There are Fortran 66 and ALGOL 60 versions of the method in the reference. I also have a modernized version here.
Let's show an example of how to use it for a simple orbital mechanics application.
Problem setup
Let's solve a trivial problem in orbital mechanics: computing the time of closest approach to a planet for a conic orbit. This is known as periapsis (or, for the Earth, perigee). We don't really need to use a minimizer to compute this, but it's a problem with a known solution that we can test the minimizer on.
We need various algorithms to do this:
Given an initial elliptical orbit state, the Gooding routine pv3els will compute the time since last periapsis passage, so we have the "true" value to compare the results against. The function we pass to fmin to minimize will simply propagate the state (the independent variable is \(\Delta t\)) and return the radius magnitude (\(r\)). The point where the radius magnitude is minimized is the periapsis point we are looking for. The orbital period is used to set the upper time bound for the minimizer (we know there is only one periapsis passage per orbital period).
Example code
In our Fortran Package Manager manifest file, we define the two external dependencies we need:
[dependencies]
fmin = { git="https://github.com/jacobwilliams/fmin.git" }
fortran-astrodynamics-toolkit = { git="https://github.com/jacobwilliams/fortran-astrodynamics-toolkit.git" }
And the main program looks like this:
program main
use fmin_module, wp => fmin_rk
use fortran_astrodynamics_toolkit
implicit none
real(wp) :: p !! semiparameter [km]
real(wp) :: period !! orbital period [sec]
real(wp) :: dt !! time from initial state to periapsis [sec]
real(wp),dimension(3) :: r, v !! position and velocity vectors [km] and [km/s]
real(wp),dimension(6) :: rv0 !! initial state vector [km, km/s]
real(wp),dimension(6) :: e0 !! Gooding orbital elements of the initial state
integer :: n_evals = 0 !! number of function evaluations
! initial conditions (orbital elements):
real(wp),parameter :: mu = 398600.4418_wp !! Earth grav. parameter [km^3/s^2]
real(wp),parameter :: a = 7000.0_wp !! semi-major axis [km]
real(wp),parameter :: ecc = 0.2_wp !! eccentricity
real(wp),parameter :: inc = 30.0_wp !! inclination [deg]
real(wp),parameter :: raan = 40.0_wp !! right ascension of ascending node [deg]
real(wp),parameter :: aop = 60.0_wp !! argument of perigee [deg]
real(wp),parameter :: tru = -45.0_wp !! true anomaly [deg]
real(wp),parameter :: tol = 1.0e-6_wp !! tolerance for fmin
! get the initial state vector and time from periapsis for the initial state:
p = a * (1.0_wp - ecc**2)
period = orbit_period(mu,a)
call orbital_elements_to_rv(mu, p, ecc, inc, raan, aop, tru, r, v)
rv0 = [r, v]
call pv3els (mu, rv0, e0) ! e0(6) is the time from periapsis of the initial state
! call the minimizer:
dt = fmin(func,0.0_wp,period,tol)
! print results
write(*,'(A,F12.6,A)') 'DT to periapsis from fmin = ', dt, ' sec'
write(*,'(A,F12.6,A)') 'True initial time from periapsis = ', e0(6), ' sec'
write(*,'(A,E12.3,A)') 'Error = ', dt + e0(6), ' sec'
write(*,'(A,I0,A)') 'number of function evals = ', n_evals, ' '
contains
function func(x) result(f)
!! the function is to propagate from the initial state
!! by the dt and compute the radius value
real(wp),intent(in) :: x !! indep. variable (dt)
real(wp) :: f !! function value `f(x)` - radius magnitude
real(wp),dimension(6) :: rvf
call propagate(mu, rv0, x, rvf)
f = norm2(rvf(1:3))
n_evals = n_evals + 1
end function func
end program main
Easy peasy!
Results
The result of running this program is:
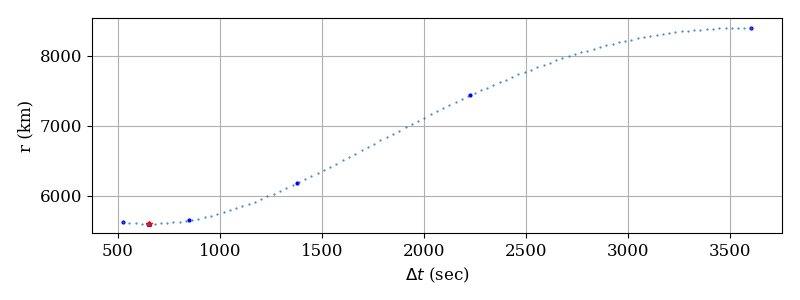
DT to periapsis from fmin = 652.983248 sec
True initial time from periapsis = -652.983240 sec
Error = 0.875E-05 sec
number of function evals = 12
So, it works! Using 12 function evaluations (i.e., kepler propagations of the orbit), the method has located the periapsis time to within about 8 \(\mu s\).
This sort of approach can also be used for less-trivial problems where we don't have a good analytical solution, and/or derivatives are unavailable or hard to obtain.
References
- R. Brent, "Algorithms for Minimization Without Derivatives", Prentice-Hall, 1973.
Jun 13, 2026

Reference [1] describes a numerical method for computing the derivative of a 1D function, using Neville's algorithm to extrapolate from a sequence of simple polynomial approximations based on interpolating points within specific bounds of a given point.
The original code in the published paper in 1980 was written in ALGOL 60. It seems as if a Fortran 77 translation was produced by David Kahaner at NIST circa 1989. I found the file on this NIST server where it has been sitting quietly since 1992 (originally this was an ftp server when I first found it). It's an interesting algorithm, and I included a modernized version in my NumDiff numerical differentiation library.
I also note that a version of the code is embedded within the Dataplot package.
But, there is a problem!
Here is a line of code in the original faccuracy function:
IF 16*ABS(H1)>ABS(H0) THEN H1:=SIGN(H1)*ABS(H0)/16;
Now, I know nothing about ALGOL 60, except that apparently John Backus (the creator of Fortran) was one of the committee members that developed it. Notice the SIGN function in this code.
This line was translated into Fortran 77 (where the function is renamed as FACCUR) as:
IF(16.*ABS(H1) .GT. ABS(H0)) H1 = SIGN(H1,1.)*ABS(H0)/16.
They are very similar, but note the SIGN function again.
In Fortran, the SIGN function (added in Fortran 77) is a little different since it has two arguments. While more flexible, it is a never-ending source of confusion, and I always have to look up the meaning of the two arguments. The following table summarizes the difference between the two:
| Language |
Syntax |
Description |
Reference |
| ALGOL 60 |
sign(E) |
the sign of the value of E (+1 for E>0, 0 for E=0, -1 for E<0) |
[2] |
| Fortran |
sign(A, B) |
the value of A with the sign of B |
[3] |
So, do you see the bug? SIGN(H1,1.) doesn't return the same thing that SIGN(H1) did in the original code. SIGN(H1,1.) returns the value of H1 with the sign of 1.0, which is always +H1, not the original intent at all! It really should have been translated to SIGN(1.0,H1), to give the +1/-1 of the original code. So, this bug is over 30 years old. Technically, the 0 case is still not handled the same, but that's a degenerate case that would never happen or give meaningful results in this context. But to be totally faithful we would need to use a function like this:
elemental real(wp) function sign_algol(x)
real(wp),intent(in) :: x
sign_algol = merge(0.0_wp, sign(1.0_wp,x), x==0.0_wp)
end function sign_algol
Other Languages
Python doesn't have a built-in sign function, but the numpy one behaves exactly like the ALGOL one. The advantage of the Fortran one is that it does support signed zeros, which the Numpy one does not appear to support (for that you need to use copysign). C++ also has a copysign function that does the same thing.
References
- J. Oliver, "Algorithm 017: An algorithm for numerical differentiation of a function of one real variable", Journal of Computational and Applied Mathematics 6 (2) (1980) 145-160. Fortran 77 code from NIST.
- J. W. Backus, F. L. Bauer, J. Green, C. Katz, J. McCarthy, A. J. Perlis, H. Rutishauser, K. Samelson, B. Vauquois, J. H. Wegstein, A. van Wijngaarden, M. Woodger Editor: P. Naur, "Revised Report on the Algorithmic Language ALGOL 60", Communications of the ACM, Volume 6, Issue 1
Pages 1 - 17, 01 January 1963.
- SIGN — Sign copying function [gcc.gnu.org]
- Numerical Differentiation, degenerateconic.com, Dec 04, 2016
Apr 26, 2025

The dark ages of confusion about where to get and how to install a Fortran compiler for your platform are over. In recent years, along with the overall renaissance of the Fortran ecosystem, with the conda package manager and the conda-forge package repository, we now have have easy access to all these free compilers for the three major platforms (Windows, Linux, and Mac):
Notes: †† gfortran is the venerable GNU Fortran compiler, the most mature open source Fortran compiler currently available. *ifx is Intel's replacement for ifort using an LLVM backend. It is free but not open source. They did not port it to the Mac ARM architecture, so that version of the compiler does not exist. On Windows, ifx still requires a Visual Studio installation to work.
‡flang (a.k.a. flang-new) is the official LLVM Fortran compiler.
†LFortran, which also uses LLVM, is still under development and is currently an "alpha" product.
There is occasionally hand-wringing from some folks (e.g., SciPy, Los Alamos, etc.) that relying on Fortran compilers is somehow a risky proposition. But it has literally never been easier to install an up-to-date modern compiler for all platforms.
Using conda, installing and trying out a Fortran compiler nowadays is as simple as this:
conda create --prefix ./env gfortran
conda activate ./env
gfortran --version
In addition, a lot of other tools that a Fortran programmer needs nowadays are also available via conda-forge. For example:
- fpm -- Fortran Package Manager
- ford -- Automatically generates Fortran documentation from comments within the code
- fortls -- Fortran Language Server
- fprettify -- Auto-formatter for modern fortran source code
- findent -- Indent, relabel and convert Fortran sources
And you can also find other developer tools you may need including:
- Python (and all the various Python libraries)
- Cmake -- A Powerful Software Build System
- Meson -- Open source build system meant to be both extremely fast, and, even more importantly, as user friendly as possible.
- Ninja -- A small build system with a focus on speed.
- git -- Distributed version control system
So, basically, you can get started with just one command:
conda create --channel conda-forge --prefix ./env gfortran fpm ford fortls fprettify findent cmake meson python git ninja
And it can all be installed in your user directory without requiring admin privileges on the machine (and if you want to remove it just delete that env folder and you are done).
If you are using VSCode, you also will want to install the Modern Fortran extension.
Then from the command palette, you can select "Python: Select Interpreter" and choose the env environment folder you created above. Then you are off to the races.
The conda distribution I recommend is miniforge. This is a version of conda that, by default, uses the conda-forge package channel rather than the commercial Anaconda channels which require a license to use. Note that conda itself is and has always been a free and open source project, so don't let your confused IT department get away with telling you it requires a paid license to use.
Another newer tool is pixi by the folks at prefix.dev. This is billed as a "fast software package manager built on top of the existing conda ecosystem". The syntax and some of the concepts are a little different, but it's an alternative way to install and use conda packages, and also works great.
See also
- Fortran Compilers at fortran-lang.org.
- Navigating Anaconda Licensing Changes: What You Need to Know, Sep 7, 2024.
- LLVM Fortran Levels Up: Goodbye flang-new, Hello flang!, LLVM Project Blog, David Spickett, Mar 11, 2025.
- 7 Reasons to Switch from Conda to Pixi, Wolf Vollprecht, March 1, 2024.
Oct 12, 2022

Image created with the assistance of NightCafe Creator.
Historically, large general-purpose libraries have formed the core of the Fortran scientific ecosystem (e.g., SLATEC, or the various PACKS). Unfortunately, as I have mentioned here before, these libraries were written in FORTRAN 77 (or earlier) and remained unmodified for decades. The amazing algorithms continued within them imprisoned in a terrible format that nobody wants to deal with anymore. At the time they were written, they were state of the art. Now they are relics of the past, a reminder of what might have been if they had continued to be maintained and Fortran had continued to remain the primary scientific and technical programming language.
Over the last few years, I've managed to build up a pretty good set of modern Fortran libraries for technical computing. Some are original, but a lot of them include modernized code from the libraries written decades ago. The codes still work great (polyroots-fortran contains a modernized version of a routine written 50 years ago), but they just needed a little bit of cleanup and polish to be presentable to modern programmers as something other than ancient legacy to be tolerated but not well maintained (which is how Fortran is treated in the SciPy ecosystem).
Here is the list:
| Catagory |
Library |
Description |
Release |
| Interpolation |
bspline-fortran |
1D-6D B-Spline Interpolation |
 |
| Interpolation |
regridpack |
1D-4D linear and cubic interpolation |
 |
| Interpolation |
finterp |
1D-6D Linear Interpolation |
 |
| Interpolation |
PCHIP |
Piecewise Cubic Hermite Interpolation Package |
 |
| Plotting |
pyplot-fortran |
Make plots from Fortran using Matplotlib |
 |
| File I/O |
json-fortran |
Read and write JSON files |
 |
| File I/O |
fortran-csv-module |
Read and write CSV Files |
 |
| Optimization |
slsqp |
SLSQP Optimizer |
 |
| Optimization |
fmin |
Derivative free 1D function minimizer |
 |
| Optimization |
pikaia |
Pikaia Genetic Algorithm |
 |
| Optimization |
simulated-annealing |
Simulated Annealing Algorithm |
 |
| One Dimensional Root-Finding |
roots-fortran |
Roots of continuous scalar functions of a single real variable, using derivative-free methods |
 |
| Polynomial Roots |
polyroots-fortran |
Root finding for real and complex polynomial equations |
 |
| Nonlinear equations |
nlesolver-fortran |
Nonlinear Equation Solver |
 |
| Ordinary Differential Equations |
dop853 |
An explicit Runge-Kutta method of order 8(5,3) |
 |
| Ordinary Differential Equations |
ddeabm |
DDEABM Adams-Bashforth algorithm |
 |
| Numerical Differentiation |
NumDiff |
Numerical differentiation with finite differences |
 |
| Numerical integration |
quadpack |
Modernized QUADPACK Library for 1D numerical quadrature |
 |
| Numerical integration |
quadrature-fortran |
1D-6D Adaptive Gaussian Quadrature |
 |
| Random numbers |
mersenne-twister-fortran |
Mersenne Twister pseudorandom number generator |
 |
| Astrodynamics |
Fortran-Astrodynamics-Toolkit |
Modern Fortran Library for Astrodynamics |
 |
| Astrodynamics |
astro-fortran |
Standard models used in fundamental astronomy |
 |
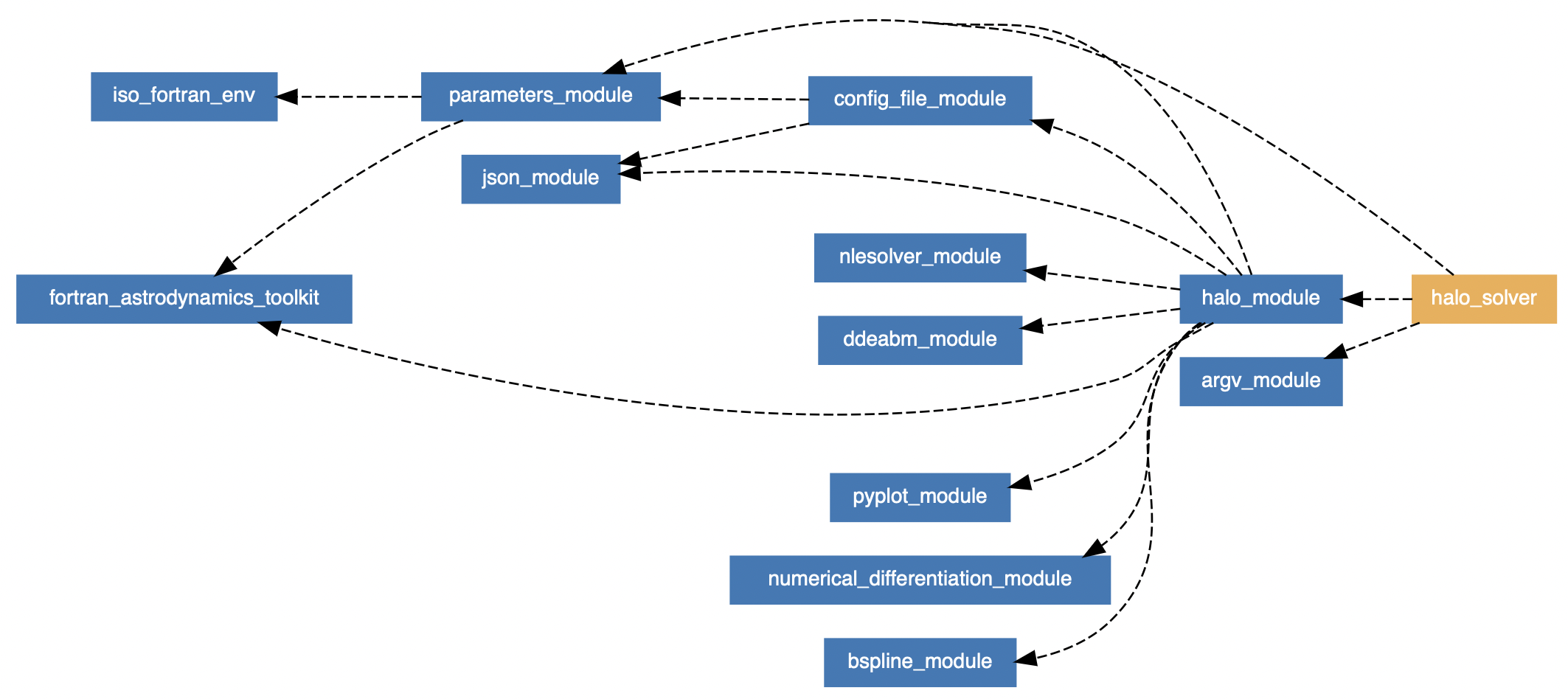
*Example of module dependencies in a Fortran application. This is for the [Halo solver](https://jacobwilliams.github.io/halo/lists/modules.html).*
All of these libraries satisfy my requirements for being part of a modern Fortran scientific ecosystem:
- All are written in a modern Fortran style (free-form, modules, no obsolete constructs such as gotos or common blocks, etc.) All legacy code has been modernized.
- They are all usable with the Fortran Package Manager. A couple of previous posts here and here show how easy it is to do this with a one-line addition to your FPM manifest file.
- The real kind (single, double, or quad precision) is selectable via a preprocessor directive.
- All libraries are available in git repositories on GitHub and contributions are welcome. Every commit is unit tested using GitHub CI.
- All the sourcecode is documented online using FORD.
- All have permissive licenses (e.g., BSD-3) so you can use them however you want.
Fortran has many advantages for scientific computing. It's fast, standard, statically typed, compiled, stable, has a nice array syntax, and includes object oriented programming and native parallelism. It is great for technical and numerical codes that need to run fast and are intended to be used for decades. The libraries listed above will not stop working in a few years. An extremely complicated Fortran application can be recompiled with just a Fortran compiler. You cannot say the same for anything written in the Python scientific ecosystem, which is a Frankenstein hybrid of a scripting language hacked together with a pile of C/C++/Fortran libraries compiled by somebody else. Good luck trying to run Python you write now 20 years from now (or trying to run something written 20 years ago). Fortran is a simple and stable foundation upon which to build our scientific software, Python is not. Having readily available modern libraries along with recent improvements in the Fortran tooling and ecosystem should only serve to make Fortran more appealing in this area.
See also
Jun 19, 2022

[NightCafe](https://creator.nightcafe.studio/) AI generated image for "old computers"
The classic Fortran routines r1mach (for single precision real numbers), d1mach (for double precision real numbers), and i1mach (for integers) were originally written in the mid-1970s for the purpose of returning basic machine or operating system dependent constants in order to provide portability. Typically, these routines had a bunch of commented out DATA statements, and the user was required to uncomment out the ones for their specific machine. The original versions included constants for the following systems:
Over the years, various versions of these routines have been created:
In the Fortran 90 versions, the original routines were modified to use various intrinsic functions available in Fortran 90. However, some hard-coded values remained in i1mach. With the advent of more recent standards, it is now possible to provide modern and completely portable versions which are described below. Starting with the Fortran 90 versions, the following changes were made:
- The routines are now in a module. We declare two module parameters which will be used in the routines:
integer, parameter :: sp = kind(1.0) ! single precision kind
integer, parameter :: dp = kind(1.0d0) ! double precision kind
Of course, putting them in a module means that they are not quite drop-in replacements for the old routines. If you want to use this module with legacy code, you'd have to update your code to add a use statement. But that's the way it goes. Nobody should be writing Fortran anymore that isn't in a module, so I'm not going to encourage that.
-
The comment strings have been updated to Ford-style. I find the old SLATEC comment block style extremely cluttered. Various cosmetic changes were also made (e.g., changing the old .GE. to >=, etc.)
-
All three routines were made pure. The error stop construct was used for the out of bounds input condition (Fortran 2008 allows error stop in pure procedures).
-
New intrinsic constants available in the Fortran 2008 standard were employed (see below).
The new routines can be found on GitHub. They are shown below without the comment blocks.
The new routines
The new d1mach routine is:
D1MACH
pure real(dp) function d1mach(i)
integer, intent(in) :: i
real(dp), parameter :: x = 1.0_dp
real(dp), parameter :: b = real(radix(x), dp)
select case (i)
case (1); d1mach = b**(minexponent(x) - 1) ! the smallest positive magnitude.
case (2); d1mach = huge(x) ! the largest magnitude.
case (3); d1mach = b**(-digits(x)) ! the smallest relative spacing.
case (4); d1mach = b**(1 - digits(x)) ! the largest relative spacing.
case (5); d1mach = log10(b)
case default
error stop 'Error in d1mach - i out of bounds'
end select
end function d1mach
This is mostly just a reformatting of the Fortran 90 routine. We make x and b parameters, and use error stop for the error condition rather than this monstrosity:
WRITE (*, FMT = 9000)
9000 FORMAT ('1ERROR 1 IN D1MACH - I OUT OF BOUNDS')
STOP
R1MACH
The updated R1MACH is similar, except the real values are real(sp) (default real, or single precision):
pure real(sp) function r1mach(i)
integer, intent(in) :: i
real(sp), parameter :: x = 1.0_sp
real(sp), parameter :: b = real(radix(x), sp)
select case (i)
case (1); r1mach = b**(minexponent(x) - 1) ! the smallest positive magnitude.
case (2); r1mach = huge(x) ! the largest magnitude.
case (3); r1mach = b**(-digits(x)) ! the smallest relative spacing.
case (4); r1mach = b**(1 - digits(x)) ! the largest relative spacing.
case (5); r1mach = log10(b)
case default
error stop 'Error in r1mach - i out of bounds'
end select
end function r1mach
I1MACH
The new i1mach routine is:
pure integer function i1mach(i)
integer, intent(in) :: i
real(sp), parameter :: x = 1.0_sp
real(dp), parameter :: xx = 1.0_dp
select case (i)
case (1); i1mach = input_unit
case (2); i1mach = output_unit
case (3); i1mach = 0 ! Punch unit is no longer used
case (4); i1mach = error_unit
case (5); i1mach = numeric_storage_size
case (6); i1mach = numeric_storage_size / character_storage_size
case (7); i1mach = radix(1)
case (8); i1mach = numeric_storage_size - 1
case (9); i1mach = huge(1)
case (10); i1mach = radix(x)
case (11); i1mach = digits(x)
case (12); i1mach = minexponent(x)
case (13); i1mach = maxexponent(x)
case (14); i1mach = digits(xx)
case (15); i1mach = minexponent(xx)
case (16); i1mach = maxexponent(xx)
case default
error stop 'Error in i1mach - i out of bounds'
end select
end function i1mach
In this one, we make heavy use of constants now in the intrinsic iso_fortran_env module, including input_unit, output_unit, error_unit, numeric_storage_size, and character_storage_size. In the Fortran 90 code, the values for I1MACH(1:4) and I1MACH(6) were totally not portable. This new one is now (almost) entirely portable.
The only remaining parameter that cannot be expressed portably is I1MACH(3), the standard punch unit. If you look at the original i1mach.f from SLATEC, there were a range of values of this parameter used by various machines (e.g. 102 for the Cray, or 7 for the IBM 360/370). Hopefully, this is not something that anybody needs nowadays, so we leave it set to 0 in the updated routine. If the Fortran committee ever adds punch_unit to iso_fortran_env, then we can update it then, and this routine will finally be finished, and the promise of a totally portable machine constants routine will finally be fulfilled.
Another interesting thing to note are I1MACH(7) (which is RADIX(1)) and I1MACH(10) (which is RADIX(1.0)). There was no I1MACH parameter for RADIX(1.0D0).
There were machine architectures where I1MACH(7) /= I1MACH(10). For example, the Data General Eclipse S/200 had I1MACH(7)=2 and I1MACH(10)=16.
But, it seems unlikely that there would ever be an architecture where the radix would be different for different real kinds. So maybe we are safe?
Results
On my laptop (Apple M1) with gfortran, the three routines produce the following values:
i1mach( 1) = 5
i1mach( 2) = 6
i1mach( 3) = 0
i1mach( 4) = 0
i1mach( 5) = 32
i1mach( 6) = 4
i1mach( 7) = 2
i1mach( 8) = 31
i1mach( 9) = 2147483647
i1mach(10) = 2
i1mach(11) = 24
i1mach(12) = -125
i1mach(13) = 128
i1mach(14) = 53
i1mach(15) = -1021
i1mach(16) = 1024
r1mach( 1) = 1.17549435E-038 ( 800000 )
r1mach( 2) = 3.40282347E+038 ( 7F7FFFFF )
r1mach( 3) = 5.96046448E-008 ( 33800000 )
r1mach( 4) = 1.19209290E-007 ( 34000000 )
r1mach( 5) = 3.01030010E-001 ( 3E9A209B )
d1mach( 1) = 2.22507385850720138E-0308 ( 10000000000000 )
d1mach( 2) = 1.79769313486231571E+0308 ( 7FEFFFFFFFFFFFFF )
d1mach( 3) = 1.11022302462515654E-0016 ( 3CA0000000000000 )
d1mach( 4) = 2.22044604925031308E-0016 ( 3CB0000000000000 )
d1mach( 5) = 3.01029995663981198E-0001 ( 3FD34413509F79FF )
References
- P. A. Fox, A. D. Hall and N. L. Schryer, Algorithm 528: Framework for a portable library, ACM Transactions on Mathematical Software 4, 2 (June 1978), pp. 177-188.
- David Gay and Eric Grosse, Self-Adapting Fortran 77 Machine Constants: Comment on Algorithm 528, ACM Transactions on Mathematical Software 25, 1 (March 1999), pp. 123-126.
- Bo Einarsson, d1mach revisited: no more uncommenting DATA statements Presented at the IFIP WG 2.5 International Workshop on "Current Directions in Numerical Software and High Performance Computing", 19 - 20 October 1995, Kyoto, Japan.
- An interview with Phyllis A. Fox, Conducted by Thomas Haigh on 7 and 8 June, 2005, Short Hills, New Jersey. Interview conducted by the Society for Industrial and Applied Mathematics.
- Why no punch_unit in iso_fortran_env?, Jun 18, 2022 [Fortran-lang Discourse]
Jun 17, 2022

In today's episode of "What where the Fortran dudes in the 1980s thinking?": consider the following code, which can be found in various forms in the two SLATEC quadrature routines dgaus8 and dqnc79:
K = I1MACH(14)
ANIB = D1MACH(5)*K/0.30102000D0
NBITS = ANIB
Note that the "mach" routines (more on that below) return:
I1MACH(10) = B, the base. This is equal to 2 on modern hardware.I1MACH(14) = T, the number of base-B digits for double precision. This will be 53 on modern hardware.D1MACH(5) = LOG10(B), the common logarithm of the base.
First off, consider the 0.30102000D0 magic number. Is this supposed to be log10(2.0d0) (which is 0.30102999566398120)? Is this a 40 year old typo? It looks like they ended it with 2000 when they meant to type 3000? In single precision, log10(2.0) is 0.30103001. Was it just rounded wrong and then somebody added a D0 to it at some point when they converted the routine to double precision? Or is there some deep reason to make this value very slightly less than log10(2.0)?
But it turns out, there is a reason!
If you look at the I1MACH routine from SLATEC you will see constants for computer hardware from the dawn of time (well, at least back to 1975. It was last modified in 1993). The idea was you were supposed to uncomment the one for the hardware you were running on. Remember how I said IMACH(10) was equal to 2? Well, that was not always true. For example, there was something called a Data General Eclipse S/200, where IMACH(10) = 16 and IMACH(14) = 14. Who knew?
So, if we compare two ways to do this (in both single and double precision):
! slatec way:
anib_real32 = log10(real(b,real32))*k/0.30102000_real32; nbits_real32 = anib_real32
anib_real64 = log10(real(b,real64))*k/0.30102000_real64; nbits_real64 = anib_real64
! naive way:
anib_real32_alt = log10(real(b,real32))*k/log10(2.0_real32); nbits_real32_alt = anib_real32_alt
anib_real64_alt = log10(real(b,real64))*k/log10(2.0_real64); nbits_real64_alt = anib_real64_alt
! note that k = imach(11) for real32, and imach14 for real64
We see that, for the following architectures from the i1mach routine, the naive way will give the wrong answer:
- BURROUGHS 5700 SYSTEM (real32: 38 instead of 39, and real64: 77 instead of 78)
- BURROUGHS 6700/7700 SYSTEMS (real32: 38 instead of 39, and real64: 77 instead of 78)
The reason is because of numerical issues and the fact that the real to integer assignment will round down. For example, if the result is 38.99999999, then that will be rounded down to 38. So, the original programmer divided by a value slightly less than log10(2) so the rounding would come out right. Now, why didn't they just use a rounding function like ANINT? Apparently, that was only added in Fortran 77. Work on SLATEC began in 1977, so likely they started with Fortran 66 compilers. And so this bit of code was never changed and we are still using it 40 years later.
Numeric inquiry functions
In spite of most or all of the interesting hardware options of the distant past no longer existing, Fortran is ready for them, just in case they come back! The standard includes a set of what are called numeric inquiry functions that can be used to get these values for different real and integer kinds:
| Name |
Description |
| BIT_SIZE |
The number of bits in an integer type |
| DIGITS |
The number of significant digits in an integer or real type |
| EPSILON |
Smallest number that can be represented by a real type |
| HUGE |
Largest number that can be represented by a real type |
| MAXEXPONENT |
Maximum exponent of a real type |
| MINEXPONENT |
Minimum exponent of a real type |
| PRECISION |
Decimal precision of a real type |
| RADIX |
Base of the model for an integer or real type |
| RANGE |
Decimal exponent range of an integer or real type |
| TINY |
Smallest positive number that can be represented by a real type |
So, the D1MACH and I1MACH routines are totally unnecessary nowadays. Modern versions that are simply wrappers to the intrinsic functions can be found here, which may be useful for backward compatibility purposes when using old codes. I tend to just replace calls to these functions with calls to the intrinsic ones when I have need to modernize old code.
Updating the old code
In modern times, we can replace the mysterious NBITS code with the following (maybe) slightly less mysterious version:
integer,parameter :: nbits = anint(log10(real(radix(1.0_wp),wp))*digits(1.0_wp)/log10(2.0_wp))
! on modern hardware, nbits is: 24 for real32
! 53 for real64
! 113 for real128
Where:
wp is the real precision we want (e.g., real32 for single precision, real64 for double precision, and real128 for quad precision).radix(1.0_wp) is equivalent to the old I1MACH(10)digits(1.0_wp) is equivalent ot the old I1MACH(14)
Thus we don't need the "magic" number anymore, so it's time to retire it. I plan to make this change in the refactored Quadpack library, where these routines are being cleaned up and modernized in order to serve for another 40 years. Note that, for modern systems, this equation reduces to just digits(1.0_wp), but I will keep the full equation, just in case. It will even work on the Burroughs, just in case those come back in style.

Final thought
If you search the web for "0.30102000" you can find various translations of these old quadrature routines. My favorite is this Java one:
// K = I1MACH(14) --- SLATEC's i1mach(14) is the number of base 2
// digits for double precision on the machine in question. For
// IEEE 754 double precision numbers this is 53.
k = 53;
// r1mach(5) is the log base 10 of 2 = .3010299957
// anib = .3010299957*k/0.30102000E0;
// nbits = (int)(anib);
nbits = 53;
Great job guys!
Acknowlegments
Special thanks to Fortran-lang Discourse users @urbanjost, @mecej4, and @RonShepard in this post for helping me get to the bottom of the mysteries of this code.
See also
- P. A. Fox, A. D. Hall and N. L. Schryer, Framework for a portable library, ACM Transactions on Mathematical Software 4, 2 (June 1978), pp. 177-188.
- David Gay and Eric Grosse, d1mach revisited: no more uncommenting DATA statements, Presented at the IFIP WG 2.5 International Workshop on "Current Directions in Numerical Software and High Performance Computing", 19 - 20 October 1995, Kyoto, Japan.
- Fun with 40 year old code, June 11, 2022, [fortran-lang Discourse].
- SLATEC, May 15, 2016 [degenerateconic.com]
- Quadpack -- Modern Fortran QUADPACK Library for 1D numerical quadrature [GitHub]
- Sorting with Magic Numbers, July 5, 2014 [degenerateconic.com]
- Burroughs large systems [Wikipedia]
Mar 27, 2022

The glacially slow pace of Fortran language development continues! From the smoke-filled room of the Fortran Standards Committee, the next Fortran standard is coming along. It has not yet been given an official name but is currently referred to as "Fortran 202x" (so hopefully we will see it before the end of this decade). Recall that Fortran 90 was originally referred to as "Fortran 198x".
A document (from John Reid) describing the new features is available here and is summarized below:
- The limit on line length has been increased to ten thousand characters, and the limit on total statement length (with all continuation lines) has been increased to a million characters.
- Allocatable-length character variables were added in Fortran 2003, but were ignored by all intrinsic procedures, until now! Better late than never, I suppose. In Fortran 202x, intrinsic routines that return strings can now be passed an allocatable string and it will be auto-allocated to the correct size. This is actually a pretty great addition, since it fixes an annoyance that we've had to live with for 20 years. Of course, what we really need is a real intrinsic string class. Maybe in 20 more years we can have that.
typeof and classof. No idea what these are for. Probably a half-baked generics feature? What we really need is a real generics feature. Since that is in work for Fortran 202y I don't know why these have been added now. Probably we will discover in 10 years that these aren't good for much, but will be stuck with them until the end of time (see parameterized derived types).- Conditional expressions. This adds the dreadful C-style
(a ? b : c) conditional expression to Fortran. Somebody thought this was a good idea? This abomination can also be passed to an optional procedure argument, with a new .nil. construct to signify not present.
- Improvements to the half-baked binary, octal, and hexadecimal constants.
- Two string parsing routines (
split and tokenize) were added. These are basically Fortran 90 style string routines that I guess are OK, but why bother? Or why limit to just these two? See above comment about adding a real string class.
- Trig functions that accept input in degrees have been added (e.g.
sind, cosd, etc). These are already commonly available as extensions in many compilers, so now they will just be standardized.
- Half revolution trig function have also been added (
acospi, asinpi, etc.). I have no idea what these are good for.
- A
selected_logical_kind function was added. This was a missing function that goes along with the selected_real_kind and selected_int_kind functions that were added in Fortran 2003. Logical type parameters (e.g., logical8, logical16, etc. were also added to the intrinsic iso_fortran_env module).
- Some updates to the
system_clock intrinsic.
- Some new functions in the
ieee_arithmetic module for conformance with the 2020 IEEE standard.
- Update to the
c_f_pointer intrinsic procedure to allow for specifying the lower bound.
- New procedures were added to
iso_c_binding for conversion between Fortran and C strings. This is nice, since everyone who ever used this feature had to write these themselves. So, now they will be built in.
- A new
AT format code, which is like A, but trims the trailing space from a string. Another nice little change that will save a lot of trim() functions.
- Opening a file now includes a new option for setting the leading zeros in real numbers (print them or suppress them).
- Public namelists can now include private variables. Sure, why not?
- Some updates for coarrays (coarrays are the built-in MPI like component of Fortran).
- A new
simple procedure specification. A simple procedure is sort of a super pure procedure that doesn't reference any variables outside of the procedure. Presumably, this would allow some additional optimizations from the compiler.
- A new "multiple subscript" array feature. The syntax for this is just dreadful (using the
@ character in Fortran for the first time).
- Integer arrays can now be used to specify the rank and bounds of an array. I tried to read the description of this, but don't get it. Maybe it's useful for something.
- Can now specify the rank of a variable using an integer constant. This is nice, and makes the
rank parts of the language a little more consistent with the other parts. Again, this is something that is cleaning up a half-baked feature from a previous standard.
- Reduction specifier for
do concurrent, which is putting more OpenMP-like control into the actual language (but just enough so people will still complain that is isn't enough).
enumeration types have been added for some reason. In addition, the half-baked Fortran 2003 enum has been extended so it can now be used to create a new type. I'm not entirely sure why we now have two different ways to do this.

So, there you have it. There are some nice additions that current users of Fortran will appreciate. It will likely be years before compilers implement all of this though. Fortran 202x will be the 3rd minor update of Fortran since Fortran 2003 was released 20 years ago. Unfortunately, there really isn't much here that is going to convince anybody new to start using Fortran (or to switch from Python or Julia). What we need are major additions to bring Fortran up to speed where it has fallen behind (e.g., in such areas as generics, exception handling, and string manipulation). Or how about some radical upgrades like automatic differentiation or built-in units for variables?
References
Feb 08, 2022

There are a lot of classic Fortran libraries from the 1970s to the early 1990s whose names end in "pack" (or, more specifically, "PACK"). I presume this stands for "package", and it seems to have been a common nomenclature for software libraries back in the day. Here is a list:
| Name |
First Released |
Description |
Original Source |
Modernization efforts |
| EISPACK |
1971 |
Compute the eigenvalues and eigenvectors of matrices |
Netlib |
largely superseded by LAPACK |
| LINPACK |
1970s? |
Analyze and solve linear equations and linear least-squares problems |
Netlib |
largely superseded by LAPACK |
| FISHPACK |
1975? |
Finite differences for elliptic boundary value problems |
Netlib, NCAR |
jlokimlin |
| ITPACK |
1978? |
For solving large sparse linear systems by iterative methods |
Netlib |
|
| HOMPACK |
1979? |
For solving nonlinear systems of equations by homotopy methods |
Netlib |
HOMPACK90 |
| MINPACK |
1980 |
Nonlinear equations and nonlinear least squares problems |
Netlib |
fortran-lang |
| QUADPACK |
1980? |
Numerical computation of definite one-dimensional integrals |
Netlib |
jacobwilliams |
| FFTPACK |
1982? |
Fast Fourier transform of periodic and other symmetric sequences |
Netlib |
fortran-lang |
| ODEPACK |
1983? |
Systematized Collection of ODE Solvers |
LLNL |
jacobwilliams |
| ODRPACK |
1986? |
Weighted Orthogonal Distance Regression |
Netlib |
HugoMVale |
| FITPACK |
1993? |
For calculating splines |
Netlib |
perazz |
| NAPACK |
1988? |
Numerical linear algebra and optimization |
Netlib |
|
| MUDPACK |
1989? |
Multigrid Fortran subprograms for solving separable and non-separable elliptic PDEs |
NCAR |
|
| SPHEREPACK |
1990s? |
For modeling geophysical processes |
NCAR |
jlokimlin |
| SVDPACK |
1991 |
For computing the singular value decomposition of large sparse matrices |
Netlib |
|
| LAPACK |
1992 |
For solving systems of simultaneous linear equations, least-squares solutions of linear systems of equations, eigenvalue problems, and singular value problems |
GitHub |
Original code remains in active development. |
| PPPACK |
1992 |
For calculating splines |
Netlib |
|
| REGRIDPACK |
1994 |
For interpolating values between 1D, 2D, 3D, and 4D arrays defined on uniform or nonuniform orthogonal grids. |
? |
jacobwilliams |
| ARPACK |
1996 |
For solving large scale eigenvalue problems |
rice.edu |
arpack-ng |
Note that some of these dates are my best guesses for the original release date. I can update the table if I get better information.
LAPACK is the only one of these "packs" that has seen continuous development since it began.
But the majority of these codes were abandoned by their original developers and organizations decades ago, and they have been frozen ever since, a symptom of the overall decline in the Fortran ecosystem. Though in a state of benign neglect, they yet remain useful to the present day. For example, SciPy includes wrappers to MINPACK and QUADPACK (and lots of other FORTRAN 77 code). However, the only "upstream" for many of these packages is Netlib, a sourcecode graveyard from another time that has no collaborative component. So, mostly any updates anybody makes are never distributed to anyone else. Frequently, these codes are converted to other languages (e.g, by f2c) and fixes or updates are made in the C code that never get back into the Fortran code. I've mentioned before how Fortran users end up calling Fortran wrappers to C code that was originally converted from FORTRAN 77 code that was never modernized.
The problem is that these classic codes, while great, are not perfect. They are written in the obsolete FORTRAN 77 fixed-form style, which nobody wants anything to do with nowadays, but that continues to poison the Fortran ecosystem. They are littered with now-unnecessary and confusing spaghetti code constructs such as GOTOs and arithmetic IF statements. They are not easy to incorporate into modern codes (there is no package manager for Netlib). Development could have continued up to the present day, and each of these libraries could have state of the art, modern Fortran implementations of both the classic and the latest algorithms. Well it's not too late. We have the internet now, and ways to collaborate on code (e.g, GitHub). We can restart development of some of these libraries:
- Convert them to free-form source
- Clean up the formatting
- Remove obsolete and now-unnecessary clutter
- Clean up the doc strings so we can use FORD to auto-generate online documentation
- Put them in a module so there is no chance of calling them with the wrong input types
- Update them for multiple real kinds
- Add automated unit testing
- Add C APIs so that they can be called from C (and, more importantly, any language that is interoperable with C, such as Python)
- Start adding newer algorithms developed in recent decades
Consider QUADPACK. This library has been used for decades, and translated into numerous other programming languages. The FORTRAN 77 version is still used in SciPy. Note that recently some minor bugs where found in the decades-old code. The edits actually made it back to Netlib through some opaque process, but the comment was made "I do not expect a lots of edits on the package. It feels like a bug here and there." Unfortunately, this has been the perception of these classic libraries: the old Fortran code is used because it works but nobody really wants to maintain it. Well, I've started a complete refactor of QUADPACK, and have already added new features as well as new methods not present in the original library.
Also consider FFTPACK and MINPACK, which were recently brought under the fortran-lang group on GitHub and development restarted as community projects. Our (ambitious) goal is to try to get SciPy to use these modernized libraries instead of the old ones. Other libraries can also move in this direction. Note: we don't have forever. SciPy recently replaced FFTPACK with a new library rewritten in C++. It's inevitable that all the old FORTRAN 77 code is going to be replaced. No one wants to work with it, and for good reason.
It's time for the Fortran community to show examples of how modern Fortran upgrades to these libraries are a better option than rewriting them from scratch in another language. With a little spit and polish, these classic libraries can have decades more life left in them. There's no need for our entire scientific programming heritage to be rewritten every few years in yet another new programming language (C, C++, Matlab, Octave, R, Python, Julia, Rust, Go, Dart, Chapel, Zig, etc, etc, etc). These libraries can be used as-is in other languages such as Python, but modernizing also makes them easier to use in actual Fortran applications. We already have the new versions available for use via the Fortran Package Manager (FPM), so adding them to your Fortran project is now a simple addition to your fpm.toml file:
[dependencies]
minpack = { git="https://github.com/fortran-lang/minpack.git" }
quadpack = { git="https://github.com/jacobwilliams/quadpack.git" }
Now isn't that better than manually downloading unversioned source files from an ftp server set up before many of the people reading this were born?
Update: See also this thread at the fortran-lang Discourse.
References
- Jack Dongarra, Gene Golub, Eric Grosse, Cleve Moler, Keith Moore, "Netlib and NA-Net: building a scientific computing community", IEEE Annals of the History of Computing, 30 (2): 30-41, 2008
- Cleve Moler, A Brief History of MATLAB, MathWorks.
- J. J. Dongarra, C. B. Moler, EISPACK: A package for solving matrix eigenvalue problems.
- J. J. Moré, B. S. Garbow, and K. E. Hillstrom, User Guide for MINPACK-1, Argonne National Laboratory Report ANL-80-74, Argonne, Ill., 1980.
- Robert Piessens, Elise de Doncker-Kapenga, Christoph W. Überhuber, David Kahaner, "QUADPACK: A subroutine package for automatic integration", Springer-Verlag, ISBN 978-3-540-12553-2, 1983




