Jan 27, 2018
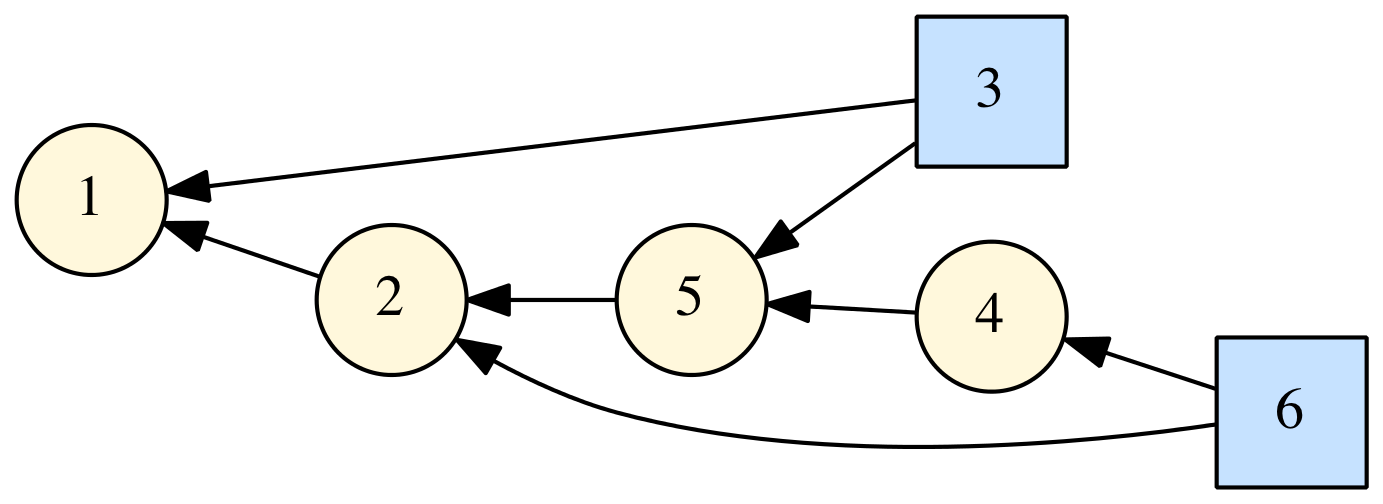
I released a new open source project on GitHub: DAGLIB, a modern Fortran library for manipulation of directed acyclic graphs (DAGs). This is based on some code I showed in a previous post. Right now, it's very basic, but you can use it to define DAGs, generate the topologically sorted order, and generate a "dot" file that can be used by GraphViz to visualize the DAG (such as the one shown at right).
In my recent AIAA paper I showed the following DAG representing how we have designed the upcoming Orion EM-1 mission:

*During Exploration Mission-1, Orion will venture thousands of miles beyond the moon during an approximately three week mission. [NASA]*
In this case, the DAG represents the dependencies among different mission attributes (which represent maneuvers, coast phases, constraints, other algorithms, etc). To simulate the entire end-to-end mission, each element must be evaluated in the correct order such that all the dependencies are met. In this same paper, we also discuss other algorithms and their implementation in modern Fortran which may be familiar to readers of this blog.
See also
- J. Williams, R. D. Falck, and I. B. Beekman. "Application of Modern Fortran to Spacecraft Trajectory Design and Optimization", 2018 Space Flight Mechanics Meeting, AIAA SciTech Forum, (AIAA 2018-1451)
- (Modern?) Fortran directed graphs library [comp.lang.fortran] May 6, 2016
- JSON-Fortran GraphViz Example (how to generate a directed graph from a JSON structure), Apr 22, 2017
- The Ins and Outs of NASA’s First Launch of SLS and Orion, NASA, Nov. 27, 2015
Dec 10, 2017

The upcoming Fortran standard formerly known as Fortran 2015 has a new name: Fortran 2018. It was decided to change it in order to match the expected year of publication. This makes sense. The previous standard (Fortran 2008) was published in 2010.
Waiting for an updated Fortran standard is an exercise in Zen-like patience. Almost a decade after Fortran 2008, we'll get a fairly minor update to the core language. And it will be years after that before it's fully supported by any compiler that most users will have available (gfortran still doesn't have a bug-free implementation of all of Fortran 2008 or even 2003). Fortran was essentially reborn in the Fortran 2003 standard, which was an amazing update that brought Fortran into the modern world. It's a terrific programming language for scientific and technical computing. However, the limitations are all too clear and have been for a long time:
- We need better facilities for generic programming. It's impossible to do some things without having to duplicate code or use "tricks" like preprocessing or include files (see JSON-Fortran for examples).
- We need some kind of exception handling. Fortran does have a floating-point exception handling feature, but honestly, it's somewhat half-baked.
- We need a better implementation of strings. Allocatable strings (introduced in Fortran 2003) are great, but not enough, since they can't be used in all instances where strings are needed.
- We need the language to be generally less verbose. I'm tired to having to type multiple nested SELECT TYPE statements to do something that is a one liner in Python (sure I know Fortran will never be as succinct as Python, but some of the verbosity required for object-oriented Fortran is just perverse).
- We need any number of new features to make it easier to extend the language with third-party libraries (so we don't have to wait two decades for a feature we want).
- We also need the language development process to embrace a more open collaborative model using modern tools (Usenet is not the future). I guess the recent survey was unprecedented, but it's not enough.

Fortran is a programming language that needs a better PR department. Legacy Fortran codes are being rewritten in C++, Python, or even Julia. NASA frequently throws massive Fortran 77 libraries with decades of heritage (e.g., DPTRAJ/ODP, GTDS, SPICELIB) into the trash in order to rewrite it all from the ground up in C++, without ever considering Fortran 2003+ (or maybe not realizing it exists?). The information about modern Fortran on the internet is spotty at best, outdated, or downright wrong (what is the deal with REAL*8?). In popular consciousness Fortran is mostly a punchline (usually something to do with punchcards and your granddad). A language like Python (which was never designed for technical computing) is now seen by many as a superior solution for technical computing. Matlab refers to itself as "the only top programming language dedicated to mathematical and technical computing"! The Julia website lists somewhat misleading benchmarks than implies that C, Julia, and even Lua are faster than Fortran.
Now, get off my lawn, you kids!

See also
Sep 12, 2017

Intel has just released version 18 of the Intel Fortran Compiler (part of Intel Parallel Studio XE 2018). At long last, this release includes full support for the Fortran 2008 standard. The updates since the previous compiler release include:
COMPILER_OPTIONS and COMPILER_VERSION in ISO_FORTRAN_ENV- Complex arguments to trigonometric and hyperbolic intrinsic functions
FINDLOC intrinsic function- Optional argument
BACK in MAXLOC and MINLOC intrinsic functions
- Multiple type-bound procedures in a
PROCEDURE list
- Passing a non-pointer data item to a pointer dummy argument
- Polymorphic assignment with allocatable Left Hand Side (LHS)
- Allocatable components of recursive type and forward reference
- Data statement restrictions removed
In addition, the new release also includes support for all the features from "Technical Specification 29113 Further Interoperability with C", planned for inclusion in Fortran 2015. These include:
- Assumed type (
TYPE(*))
- Assumed rank (
DIMENSION(..))
- Relaxed restrictions on interoperable dummy arguments
ISO_Fortran_binding.h C include file for use by C code manipulating "C descriptors" used by Fortran
Hopefully, it won't take so long to get the compiler up to full Fortran 2015 compliance (see a previous post for a list of new Fortran 2015 features).
See also
Aug 12, 2017
JPL's SPICE Toolkit (SPICELIB) is the premier software library for computations related to solar system geometry. It is freely distributed, and is also one of the best-documented libraries I have ever come across. SPICELIB also includes a comprehensive set of routines for date and time conversions. An example is shown here:
program spice_test
use iso_fortran_env, only: wp => real64
implicit none
interface
! SPICELIB routines
subroutine timout ( et, pictur, output )
import :: wp
implicit none
real(wp),intent(in) :: et
character(len=*),intent(in) :: pictur
character(len=*),intent(out) :: output
end subroutine timout
subroutine str2et ( string, et )
import :: wp
implicit none
character(len=*),intent(in) :: string
real(wp),intent(out) :: et
end subroutine str2et
subroutine furnsh ( file )
implicit none
character(len=*),intent(in) :: file
end subroutine furnsh
end interface
character(len=*),parameter :: time_in = &
'2017 Aug 12 00:00:00 TDB'
character(len=*),parameter :: pictur = &
'Mon DD,YYYY HR:MN:SC.#### UTC ::UTC'
real(wp) :: et
character(len=100) :: time_out
! load the leap second kernel:
call furnsh('naif0012.tls')
! example conversion:
call str2et(time_in, et)
call timout(et, pictur, time_out)
write(*,*) 'time_in: ', time_in
write(*,*) 'et: ', et
write(*,*) 'time_out: ', time_out
end program spice_test
A few things to note:
- Here we are using the SPICE routines str2et and timout to convert a string from a TDB calendar date to ephemeris time and then to a UTC calendar date. These routines are very flexible and can convert a wide range of date formats. Other routines are available to do other transformations.
- The base time system of SPICE is Barycentric Dynamical Time (TDB). "Ephemeris time" is a count of TDB seconds since the J2000 epoch (Jan 1, 2000 12:00:00).
- We have to load the latest leap second kernel (naif0012.tls in this case), which is necessary to define UTC.
- The SPICE routines are not in a module (the code is Fortran 77), and so have no explicit interfaces. Thus it is good practice to specify them as I do here.
The output of this example is:
time_in: 2017 Aug 12 00:00:00 TDB
et: 555768000.00000000
time_out: Aug 11,2017 23:58:50.8169 UTC
See also
Aug 11, 2017

JPL recently released an update to their awesome SPICE Toolkit (it is now at version N66). The major new feature in this release is the Digital Shape Kernel (DSK) capability to define the shapes of bodies (such as asteroids) via tessellated plate models.
Unfortunately for Fortran users, they also announced that they have decided to reimplement the entire library in C++. SPICELIB is currently written in Fortran 77, which they f2c to provide a C version (which is also callable from IDL, Matlab, and Python, among others). Their reason for this "upgrade" is to provide thread safety and object oriented features. Of course, modern Fortran can be thread safe and object oriented, and upgrading the code to modern standards could be done in a fraction of the time it will take to rewrite everything from scratch in C++. SPICELIB is extremely well-written Fortran 77 code, and is not infested with COMMON blocks, EQUIVALENCE statements, etc. I actually don't think it would take much effort to modernize it. In addition, Fortran/C interoperability could be employed to easily provide an interface that is callable from C without source transformation.
However, I guess it isn't meant to be, and the science/engineering community will lose another Fortran code to C++ like many times before, in spite of C++ being a terrible language for scientists and engineers.
See also
Aug 11, 2017

The glacially slow pace of Fortran language development continues! The next standard, Fortran 2015, mainly consists of updates for Fortran/C interoperability and new coarray features such as teams. In addition, there are a bunch of minor changes and discrepancy fixes. A few of the new features are:
- The venerable
implicit none statement has been updated to allow for some additional use related to external procedures.
- The stop code in
error stop can now be any integer or character expression.
- An
out_of_range intrinsic was added to allow for testing whether a real or integer value can be safely converted to a different real or integer type and kind.
- You can now declare the kind of the loop variable inside an implied do loop. For example:
iarray = [(2*i, integer :: i=1,n)].
- All procedures are now recursive by default. This is an interesting change. Ever since recursion was added to the language in Fortran 90, a procedure has had to be explicitly declared as
recursive. Now, you have to use non_recursive if you don't want to allow a procedure to be used recursively.
- Some new syntax to indicate the locality status of variables within a
do concurrent loop.
- There are a lot of new IEEE intrinsic routines for some reason.
Fortran 2015 is expected to be published in 2018.
See also
Jun 20, 2017

You can now try OpenCoarrays and Gfortran in the cloud, courtesy of Zaak Beekman and the Sourcery Institute. Just navigate to http://bit.ly/TryCoarrays and then click "Launch". This awesome project is enabled by various other awesome tools like Binder, Jupyter, and GitHub. Truly, we are living in the future.
Coarrays are the parallel processing component built into the Fortran language (standardized in Fortran 2008). It uses the Partitioned Global Address Space (PGAS) and Single-Program-Multiple-Data (SPMD) programming models. OpenCoarrays is an open source library to enable coarray usage in Gfortran.
See also
May 27, 2017
I happened across this article on a programming language and IDE called Xojo. I never used it under this name, but I have fond memories of using it when it was called RealBASIC. I learned it shortly after it came out in the late 1990s. I found it very intuitive and it was super easy to create fairly nice looking GUI applications for the Mac. In fact, the first optimization code I ever wrote was in RealBASIC, for solving the traveling salesman problem.
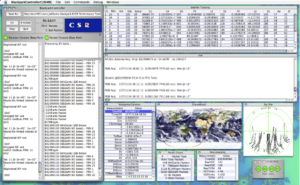
In the mid-2000's when I was a grad student, I used it to build a GUI interface to JPL's BlackJack GPS receiver. This included reading data from the receiver, as well as sending commands to it. There were numerous floating windows that displayed data and plots (see screenshot at right). At the time, JPL's interface code only ran on pre-MacOS X systems, which were rapidly becoming obsolete. My RealBASIC app ran great on MacOS X. In fact, I believe JPL requested a copy when they saw it (I have no idea if it lives on somewhere at JPL).

In 2006, I traveled to Germany with a blue clamshell iBook to deliver some updated software to the TerraSAR-X satellite, which included the same type of GPS receiver. I remember during the update process, something unexpected occurred (the details escape me now). In any event, it was required to generate some binary command files to upload to the system in order to set things right. My RealBASIC interface app was already set up to do that, so I fired up my iBook and was able to generate the files in short order. I distinctly remember some surprise from the German engineers that I could do such a thing with this silly looking machine! After uploading the files, things got back on track. TerraSAR-X has been in orbit since June 2007.
I haven't used it in years, but I'm glad to know that RealBASIC is still around.
See also
May 19, 2017

It appears that Flang, a new open source Fortran front-end for LLVM, has appeared on GitHub recently with little fanfare. This is apparently the result of NVIDIA's previously-announced plan to open source the PGI Fortran compiler. Unfortunately, they decided to give it the same name as another earlier attempt to create a Fortran/LLVM compiler (more confusion for poor Fortran programmers). I don't really know how it compares to Gfortran or Intel (PGI appears to be lagging behind on support for the Fortran 2008 standard). Initial tests by Usenet denizens (yes Usenet still exists) indicate that maybe Flang isn't quite ready for prime time. Hopefully it will improve with time. I think it's great news to potentially have another free Fortran compiler available.
See also
May 07, 2017

String and file manipulation in Fortran isn't as bad as you've heard (OK, it's bad, but it's getting better). Sure, modern Fortran only provides the bare minimum of features for this sort of thing out of the box, but various libraries are starting to appear that the modern Fortran programmer can use to deal with a range of different file formats including JSON, INI, CSV, XML, etc. The Fortran user community has been late to the game on this opensource thing. But it does exist and I encourage all Fortraners to use it. You don't have to roll your own file format or write your own parser. If the existing libraries don't have what you need, then help to improve them.
The following is a look at a few different options for configuration files in your Fortran program. It is limited to text files. For binary files, I would highly recommend a standard cross-platform format (such as HDF5). For goodness' sake, do not invent your own binary file format.
Namelists
Fortran namelists are very old-school, but are still part of the standard (indeed this is the only high-level file read/write feature that is built into Fortran). Namelist have a few advantages, but they are generally outweighed by their many disadvantages. Some advantages include:
- It is super easy to use. The reading and writing of the file is automatically handled by the compiler. A namelist is declared like so:
integer :: a
real :: b
character(len=5) :: c
integer :: iunit,istat
namelist /blah/ a,b,c
!set values:
a = 1
b = 2.0
c = 'three'
and can be written by:
write(unit=iunit, nml=blah, iostat=istat)
Which produces a file like this:
&BLAH
A= 1,
B= 2.00000000 ,
C="three",
/
The file can be read by:
read(unit=iunit, nml=blah, iostat=istat)
- It automatically handles any Fortran variables you throw at it (including multidimensional arrays and derived data types).
- Variables in the file can be optional. Any variable not present in the file retains the value it had before the namelist was read.
Disadvantages include:
- Different compilers can and will output slightly different formats, and you have absolutely no control over that.
- If you want to generate or manipulate your input files using a different language, you'll probably have to write your own parser to do it. Hardly any other programming language will have a decent namelist parser or writer available. A notable exception is f90nml, a great Python library for reading and writing namelists.
- The variables in the file must exactly correspond (in name, type, and size) to variables in the code. This turn out to be very restrictive for a lot of reasons. For one thing, it is quite annoying for strings, since it requires you to specify a maximum string length in the variable declaration.
- It can be difficult to diagnose errors when reading the file (e.g, a syntax error, an unrecognized variable, or an array size or string length larger than the Fortran variable). The compiler will usually just throw an I/O error if anything goes wrong. However, it is possible on some compilers to retrieve the line where the error occurred by rewinding one line and then reading it with a normal READ statement.
- It is difficult to tell if a variable is actually present in the file (if one isn't there, then the corresponding variable in the code will just retain whatever value it had before the read was attempted. Thus, the only real way to check if a variable was present or not is to initialize them all to unusual values, and then check for this after the read.)
In my view, there is little reason to start using namelists at this point, since there are now better options available. Unless you have a legacy code that is using them which can't be changed, I would recommend using something else.
JSON
JSON stands for JavaScript Object Notation, and is a very popular and lightweight data-interchange format. There is an interface for practically all known programming languages, including modern Fortran. My JSON-Fortran library was built on an older Fortran 95 library, which I forked in order to be able to use some of the newer Fortran 2003/2008 features. With JSON-Fortran, the example above would be:
type(json_file) :: json
call json%add('blah.a',1)
call json%add('blah.b',2.0)
call json%add('blah.c','three')
Which produces the JSON file:
{
"blah": {
"a": 1,
"b": 2.0,
"c": "three"
}
}
Note that f90nml can also be used to transition away from namelists by converting them to JSON using Python. To go from a namelist to JSON, all you have to do is this:
import f90nml
import json
n = f90nml.read('my_namelist.nml')
with open('my_namelist.json', 'w') as outfile:
json.dump(n, outfile, sort_keys = True, indent = 4)
Using my JSON-Fortran library, you can even convert a JSON file back into a Namelist if that sort of thing is your bag (as shown in a previous post). One disadvantage of JSON is that the standard does not allow for comments in the file. However, some parsers include support for comments (including JSON-Fortran).
INI
INI is a simple, easy-to-write format. Although not really standardized, it is based on the old MS-DOS initialization files. For modern Fortran, the FiNeR library provides a Fortran interface. The INI version of the above file would be:
Here's an example of converting an INI file to a JSON file (using FiNeR and JSON-Fortran):
subroutine ini2json(ini_filename, json)
use json_module
use finer
implicit none
character(len=*),intent(in) :: ini_filename
type(json_file),intent(out) :: json
type(file_ini) :: ini
integer :: ierr
integer :: i
character(len=:),dimension(:),allocatable :: secs
character(len=:),dimension(:),allocatable :: opts
call ini%load(filename=ini_filename,error=ierr)
call ini%get_sections_list(secs)
do i=1,size(secs)
do
if (.not. ini%loop(trim(secs(i)),opts)) exit
call json%add(trim(secs(i))//'.'&
trim(opts(1)),trim(opts(2)))
end do
end do
call ini%free()
end subroutine ini2json
You could call this routine like so:
program main
use ini2json_module
use json_module
implicit none
type(json_file) :: json
call ini2json('test.ini',json)
call json%print_file()
call json%destroy()
end program main
And it would produce the following result for the file above:
{
"blah": {
"a": "1",
"b": "2.0",
"c": "three"
}
}
Note that, in this example, all the variables are returned as strings (getting the numerical values as numbers is left as an exercise to the reader).
Others
- XML (Extensible Markup Language) -- I never really liked this one because it is not easily human readable or editable. There are some Fortran XML parsers out there, though.
- YAML (YAML Ain't Markup Language) -- I'm not as familiar with this one (also I hate recursive acronyms). There is a Fortran interface to it called fortran-yaml, but I haven't tried it.
- TOML (Tom's Obvious, Minimal Language) - I'm not aware of a Fortran parser for this one. This one was created by one of the founders of GitHub.
- Lua - Another interesting possibility is for your configuration file to be written in a full-up scripting language. There are a couple of Lua-Fortran interfaces out there (e.g., AOTUS).
See also
