May 06, 2018

*Altair's ascent stage docking with Orion [NASA]*
The lunar gravity field is bumpy. Thus a spacecraft in a low lunar orbit for an extended period of time must perform periodic correction maneuvers or the orbit eventually becomes unstable and can crash into the Moon. When the Orion spacecraft was being designed during the late Constellation Program, the requirements of global surface access sortie missions, six-month polar outpost missions, anytime aborts, and autonomous operation of the vehicle while the crew was on the surface, required lots of analysis to figure out how to make the architecture work. And then the program was canceled.
The reference low-lunar orbit maintenance algorithm we used during Constellation was fairly simple. Orion initially inserted into a retrograde circular parking orbit with a 100 km altitude. During orbit propagation, if the altitude was reduced by a specified deadband altitude (say 10 km) the vehicle would perform a periapsis raise maneuver at the next apoapsis to bring the periapsis back up to 100 km. The apoapsis radius was not controlled, and indeed all the other orbital elements were also allowed to float. This would continue until the crew was ready to return (on the Altiar lander ascent stage), at which point Orion would circularize the orbit and perform a plane change to allow Altair to perform an in-plane ascent.
The \(\Delta v\) maneuver to perform at apoapsis of an orbit with a periapsis radius \(r_{pi}\) and apoapsis radius \(r_{ai}\), to target a periapsis radius \(r_{pf}\) can be computed by:
- Initial apoapsis velocity: \(v_{ai} = \sqrt{ 2 \mu \frac{r_{pi}}{r_{ai} (r_{ai}+r_{pi})} }\)
- Final apoapsis velocity: \(v_{af} = \sqrt{ 2 \mu \frac{r_{pf}}{r_{ai} (r_{ai}+r_{pf})} }\)
- Maneuver magnitude: \(\Delta v = v_{af} - v_{ai}\)
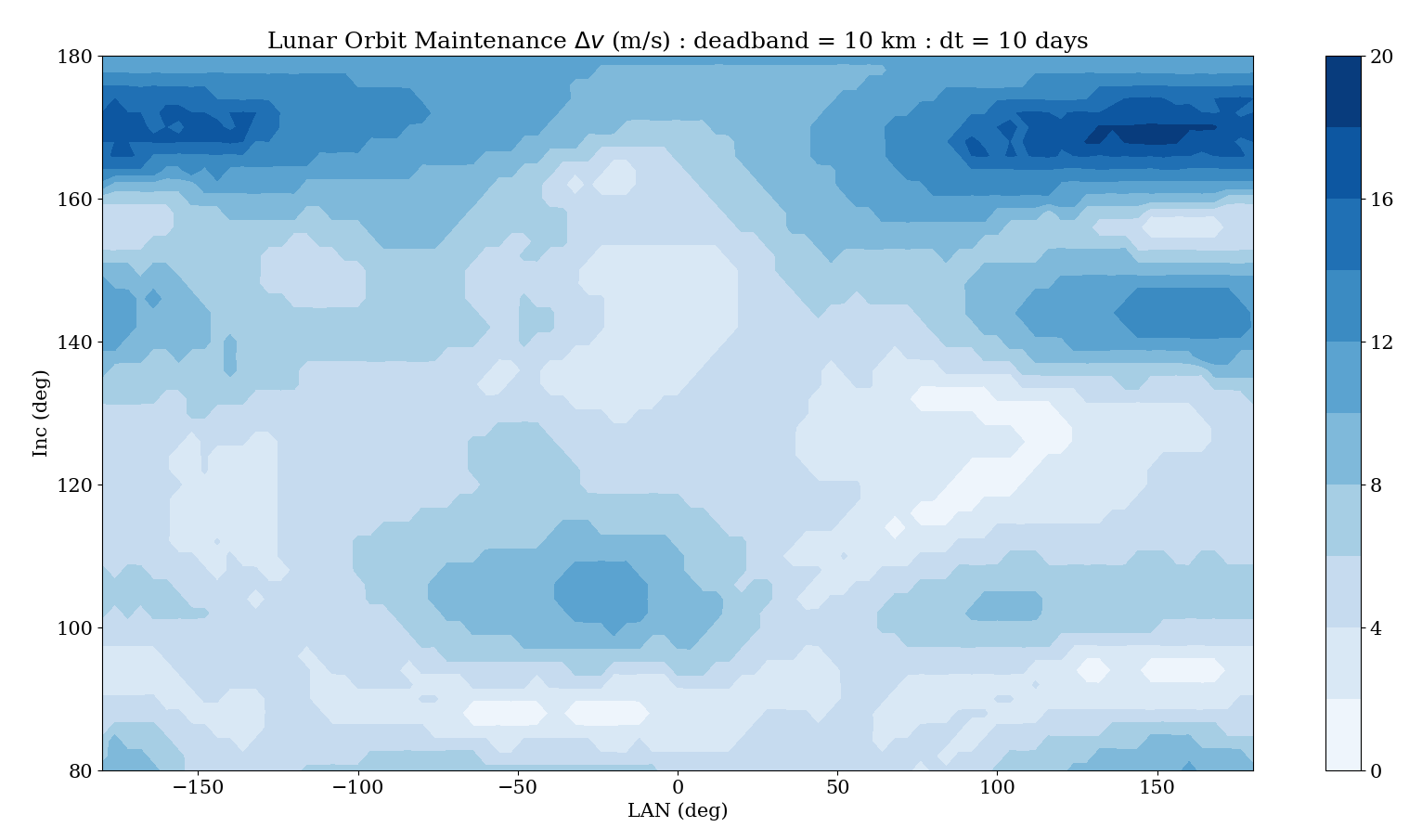
We can implement this method using the Fortran Astrodynamics Toolkit fairly easily. We also need an integrator with an event finding capability (we can use DDEABM, a variable step size variable order Adams method). We propagate from the initial insertion state until the deadband altitude is violated, then propagate to the next apoapsis where the periapsis raise maneuver is performed, then repeat as necessary. The code implementing this scheme can be found on GitHub here. For the force model, we are using a 20 x 20 GRAIL geopotential model of the Moon (not available during Constellation, when we used the Lunar Prospector derived LP150Q model). A contour plot of the results for 100 km retrograde orbits with a 10 km altitude deadband and 10 days of propagation time are shown below. Each maneuver ends up being about 2 m/s for this example, and the bumpiness of the gravity field is evident. Some insertion orbits require no maneuvers, while others require about 18 m/s over the 10 day period.
See also
- J. Williams, S. M. Stewart, D. E. Lee, E. C. Davis, G. E. Condon, J. S. Senent. "The Mission Assessment Post Processor (MAPP): A New Tool for Performance Evaluation of Human Lunar Missions", 20th AAS/AIAA Space Flight Mechanics Meeting, 14-17 February 2010, San Diego, CA.
- F.G. Lemoine, S. Goossens, T.J. Sabaka, et al. GRGM900C: A degree 900 lunar gravity model from GRAIL primary and extended mission data. Geophysical Research Letters. 2014;41(10):3382-3389.
- R. B. Roncoli, Lunar Constants and Models Document, JPL D-32296, Sept 23, 2005.
- M. Beckman, L. Rivers, Stationkeeping for the Lunar Reconnaissance Orbiter (LRO), 20th International Symposium on Space Flight Dynamics, 24-28 Sep. 2007.
Apr 04, 2018
Many of NASA's workhorse spacecraft trajectory optimization tools are written in Fortran or have Fortran components (e.g., OTIS, MALTO, Mystic, and Copernicus). None of it is really publicly-available however. There are some freely-available Fortran codes around for general-purpose orbital mechanics applications. Including:
You can also find some old Fortran gems in various papers on the NASA Technical Reports Server.
See also
- J. Williams, R. D. Falck, and I. B. Beekman. "Application of Modern Fortran to Spacecraft Trajectory Design and Optimization", 2018 Space Flight Mechanics Meeting, AIAA SciTech Forum, (AIAA 2018-1451)
Mar 10, 2018
OpenCoarrays 2.0.0 has been released. According to the release notes, this release adds support for:
- Fortran 2018 teams (note that this requires the use of GFortran 8.x, currently under development)
- Fortran 2018
QUIET specifier in STOP and ERROR STOP statements
- Fortran 2008 allocatable & pointer components of derived-type coarrays
Since Fortran 2008 (with the inclusion of coarrays in the standard), Fortran has been a PGAS programming language. Fortran 2018 adds additional enhancements for coarrays (including the teams feature, and support for detection of failed images). OpenCoarrays is an open source (permissive BSD license) library that enables coarray support in the GFortran compiler.
See also
Feb 17, 2018
A standard way to access a program's command line arguments wasn't added to Fortran until 2003. Command line arguments were one of those things (like environment variables, the file system, and the operating system shell) that the Fortran standards committee pretended didn't exist or wasn't important. Of course, that was and is ridiculous. So for decades, all Fortran compilers provided a non-standard way to get the command line arguments (for example, GETARG in gfortran). Currently, the standards committee still pretends that the file system doesn't exist (for example, there's no standard way to change an application's working directory, or list the files in a directory, or even to check for the existence of directories). But I digress.
The two routines you need to know are COMMAND_ARGUMENT_COUNT and GET_COMMAND_ARGUMENT. Frequently in examples on the internet (even the gfortran example) you will see people just declare a really long string and use GET_COMMAND_ARGUMENT to get the command line argument and hope for the best. That's terrible of course, since this routine does have the ability to return the actual length of the argument, so you should use that to allocate a string with the correct size to hold it.
Consider the following example:
module command_line_module
implicit none
private
type,public :: string
!! a variable-length string type
character(len=:),allocatable :: str
end type
public :: get_command_arguments
contains
subroutine get_command_arguments(nargs, args)
!! return all the command line arguments.
!! (each one is the correct size)
implicit none
integer,intent(out) :: nargs !! number of arguments
type(string),dimension(:),allocatable,intent(out) :: args
integer :: i, ilen
nargs = command_argument_count()
allocate(args(0:nargs))
do i = 0, nargs
call get_command_argument(i,length=ilen)
allocate(character(len=ilen) :: args(i)%str)
call get_command_argument(i,value=args(i)%str)
end do
end subroutine get_command_arguments
end module command_line_module
Here we have to define our own string type (string), so we can create an array of deferred-length strings (since a useful varying-length string type is another thing Fortran pretends is not important). See StringiFor for a full-featured variable-string type, but for our purposes here the simple one is fine. The procedure in the get_command_arguments() routine is to check for the size of each argument, allocate a string large enough to hold it, and then retrieve the value. It returns an array of string variables containing the command line arguments. With a wrapper module like this, getting command line arguments is effortless, and there is no reason anymore to use the old non-standard routines.
Feb 10, 2018
It looks like the Fortran community has lost another venerable NASA Fortran library to C++. I recently noticed that the latest release of NASA's Global Reference Atmosphere Model (GRAM) is now C++. From the release link:
Earth-GRAM 2016 is now available as an open-source C++ computer code that can run on a variety of platforms including PCs and UNIX stations. The software provides a model that offers values for atmospheric parameters such as density, temperature, winds, and constituents for any month and at any altitude and location within the Earth's atmosphere. Earth-GRAM 2010 is available in FORTRAN. Similar computer models of Mars, Venus, Titan, and Neptune are available for diverse mission applications through NASA’s Space Environments and Effects (SEE) Program, a partnership with industry, academia, and other government agencies that seeks to develop more reliable, more effective spacecraft.

The Earth-GRAM model, originally written in Fortran 77, is produced by MSFC and has been around for a while, with many revisions (i.e., GRAM-86, GRAM-88, GRAM-90, GRAM-95, GRAM-99, GRAM 2007, and GRAM 2010). In the 2010 revision, they converted the old Fortran 77 code to Fortran 90, which I thought was a step in the right direction (although maybe 20 years too late). It seems like they could have used Fortran 2003 and provided a C interface using the standard Fortran/C Interoperability feature, which would have enabled calling it from a variety of languages (including C++).
I remain utterly unconvinced that C++ is the programming language that engineers and scientists should be using. Are CS people taking over programming jobs once done by engineers? Is this a failure of university engineering departments? Although it seems like even CS people don't want to be using C++ anymore. Every time I turn around a new programming language (Java, Rust, Go, D, C#, Swift, ...) is created by CS people fed up with the C++ dumpster fire. So I don't know who is telling engineers that C++ is the future. And the perception that Fortran is an obsolete programming language is very strong, even within the engineering/technical disciplines that it was designed for. Sometimes this is due to sheer ignorance, but sometimes it is due to ancient Fortran 77 legacy code that people have to deal with. I sympathize with them, Fortran 77 code is terrible and needs to go away, but it should be modernized, not thrown out and replaced with C++. Think of the children! (and the memory leaks!)
Parting words of wisdom
Security tips when programming in C (2017 edition):
1) Stop typing
2) Delete what you've already typed
— ryan huber (@ryanhuber) June 21, 2017
See also
- Earth-GRAM 2016 is now available!
- Earth Global Reference Atmospheric Model (Earth-GRAM 2010) -- The last Fortran 90 release. [request here]
- F.W. Leslie, C.G. Justus, "The NASA Marshall Space Flight Center Earth Global Reference Atmospheric Model—2010 Version", NASA/TM—2011–216467, 2011
- ModelWeb Catalogue and Archive -- other atmosphere models listed on GSFC ModelWeb
- D. L. Johnson, R. Blocker, C. G. Justus, Global Reference Atmosphere Model (GRAM), NASA Tech Brief, MFS-28397, Jan 01, 1993
Feb 05, 2018

I have mentioned various kinds of configuration file formats used in Fortran here before. One that I haven't mentioned is the text PCK file format used by the NAIF SPICE Toolkit. This is a format that is similar in some ways to Fortran namelists, but with a better API for reading the file and querying the contents. Variables read from a PCK file are inserted into the SPICE variable pool. An example PCK file (pck00010.tpc) can be found here.
The PCK file format has some limitations. It doesn't allow inline comments (only block comments separate from the variable declarations). Integers are stored as rounded doubles, and logical variables are not supported at all (you have to use 0.0 or 1.0 for this). One particular annoyance is that the files are not cross platform (the line breaks must match the platform they are being used on). However, SPICELIB also provides routines to programmatically enter variables into the pool. This allows us to create files in other formats that can be used in a SPICE application. For example, we can use JSON-Fortran to read variables in JSON files and insert them into the SPICE pool.
First, let's declare the interfaces to the SPICE routines we need (since SPICELIB is straight up Fortran 77, they are not in a module):
interface
subroutine pcpool ( name, n, cvals )
implicit none
character(len=*) :: name
integer :: n
character(len=*) :: cvals ( * )
end subroutine pcpool
subroutine pdpool ( name, n, values )
import :: wp
implicit none
character(len=*) :: name
integer :: n
real(wp) :: values ( * )
end subroutine pdpool
subroutine pipool ( name, n, ivals )
implicit none
character(len=*) :: name
integer :: n
integer :: ivals ( * )
end subroutine pipool
subroutine setmsg ( msg )
implicit none
character(len=*) :: msg
end subroutine setmsg
subroutine sigerr ( msg )
implicit none
character(len=*) :: msg
end subroutine sigerr
end interface
Then, we can use the following routine:
subroutine json_to_spice(jsonfile)
implicit none
character(len=*),intent(in) :: jsonfile
!! the JSON file to load
integer :: i,j
type(json_core) :: json
type(json_value),pointer :: p,p_var,p_element
real(wp) :: real_val
integer :: var_type,int_val,n_vars,n_children,element_var_type
logical :: found
integer,dimension(:),allocatable :: int_vec
real(wp),dimension(:),allocatable :: real_vec
character(len=:),dimension(:),allocatable :: char_vec
character(len=:),allocatable :: char_val,name
integer,dimension(:),allocatable :: ilen
nullify(p)
! allow for // style comments:
call json%initialize(comment_char='/')
! read the file:
call json%parse(file=jsonfile, p=p)
if (json%failed()) then
! we will use the SPICE error handler:
call setmsg ( 'json_to_spice: Could not load file: '&
trim(jsonfile) )
call sigerr ( 'SPICE(INVALIDJSONFILE)' )
else
! how many variables are in the file:
call json%info(p,n_children=n_vars)
main : do i = 1, n_vars
call json%get_child(p, i, p_var, found)
! what kind of variable is it?:
call json%info(p_var,var_type=var_type,name=name)
if (var_type == json_array) then
! how many elements in this array?:
call json%info(p_var,n_children=n_children)
! first make sure all the variables are the same type
! [must be integer, real, or character]
do j = 1, n_children
call json%get_child(p_var, j, p_element, found)
call json%info(p_element,var_type=element_var_type)
if (j==1) then
var_type = element_var_type
else
if (var_type /= element_var_type) then
call setmsg ( 'json_to_spice: Invalid array ('&
trim(name)//') in file: '//trim(jsonfile) )
call sigerr ( 'SPICE(INVALIDJSONVAR)' )
exit main
end if
end if
end do
! now we know the var type, so get as a vector:
select case (var_type)
case(json_integer); call json%get(p_var,int_vec)
case(json_double ); call json%get(p_var,real_vec)
case(json_string ); call json%get(p_var,char_vec,ilen)
case default
call setmsg ( 'json_to_spice: Invalid array ('&
trim(name)//') in file: '//trim(jsonfile) )
call sigerr ( 'SPICE(INVALIDJSONVAR)' )
exit main
end select
else
! scalar:
n_children = 1
select case (var_type)
case(json_integer)
call json%get(p_var,int_val); int_vec = [int_val]
case(json_double )
call json%get(p_var,real_val); real_vec = [real_val]
case(json_string )
call json%get(p_var,char_val); char_vec = [char_val]
case default
call setmsg ( 'json_to_spice: Invalid variable ('&
trim(name)//') in file: '//trim(jsonfile) )
call sigerr ( 'SPICE(INVALIDJSONVAR)' )
exit main
end select
end if
! now, add them to the pool:
select case (var_type)
case(json_integer)
call pipool ( name, n_children, int_vec )
case(json_double )
call pdpool ( name, n_children, real_vec )
case(json_string )
call pcpool ( name, n_children, char_vec )
end select
end do main
end if
call json%destroy(p)
end subroutine json_to_spice
Here we are using the SPICE routines PIPOOL, PDPOOL, and PCPOOL to insert variables into the pool. We are also using the built-in SPICE error handling routines (SETMSG and SIGERR) to manage errors. The code works for scalar and array variables. It can be used to read the following example JSON file:
{
"str": "qwerty", // a scalar string
"strings": ["a", "ab", "abc", "d"], // a vector of strings
"i": 8, // a scalar integer
"ints": [255,127,0], // a vector of integers
"r": 123.345, // a scalar real
"reals": [999.345, 5671.8] // a vector of reals
}
After reading it, we can verify that the variables were added to the pool by printing the pool contents using the routine WRPOOL. This produces:
\begindata
str = 'qwerty'
i = 0.80000000000000000D+01
strings = ( 'a',
'ab',
'abc',
'd' )
ints = ( 0.25500000000000000D+03,
0.12700000000000000D+03,
0.00000000000000000D+00 )
r = 0.12334500000000000D+03
reals = ( 0.99934500000000003D+03,
0.56718000000000002D+04 )
\begintext
See also
Feb 01, 2018

The IAU Standards of Fundamental Astronomy (SOFA) library implements standard models used in fundamental astronomy. Version 14 ( 2018-01-30) has just been released. According to the release notes, this update includes the following:
- Change in the copyright status of the iau_DAT routine. This is to provide for a user-supplied mechanism for updating the number of leap seconds. SOFA doesn't provide any such mechanism, but they are now allowing you to replace or modify this routine to provide your own without having to rename the routine (all other SOFA routines cannot be modified without renaming them).
- Implementation of two new categories of routines:
- Three new routines for the horizon/equatorial plane coordinates.
- iau_AE2HD — (azimuth, altitude) to (hour angle, declination)
- iau_HD2AE — (hour angle, declination) to (azimuth, altitude)
- iau_HD2PA — parallactic angle
- Six new routines dealing with gnomonic (tangent plane) projections.
- iau_TPORS — solve for tangent point, spherical
- iau_TPORV — solve for tangent point, vector
- iau_TPSTS — project tangent plane to celestial, spherical
- iau_TPSTV — project tangent plane to celestial, vector
- iau_TPXES — project celestial to tangent plane, spherical
- iau_TPXEV — project celestial to tangent plane, vector
- The Astrometry Tools Cookbook, the test program and other supporting files have also been updated.
- Other minor documentation/typographical corrections to various files.
IAU SOFA has a Fortran 77 and a C version. While this is a great resource, I do wonder why the IAU insists on using a source format for the Fortran version that was rendered obsolete 30 years ago? There's no reason for this. This is new code that is regularly kept up to date, so why not modernize it for those of us living in the 21st century?
Consider this SOFA routine:
SUBROUTINE iau_TR ( R, RT )
IMPLICIT NONE
DOUBLE PRECISION R(3,3), RT(3,3)
DOUBLE PRECISION WM(3,3)
INTEGER I, J
DO 2 I=1,3
DO 1 J=1,3
WM(I,J) = R(J,I)
1 CONTINUE
2 CONTINUE
CALL iau_CR ( WM, RT )
END SUBROUTINE iau_TR
All this is doing is transposing a 3x3 matrix. Well, since the late 1990s, to do that in Fortran all you need is:
The original routine is just awful: all caps, line numbers, CONTINUE statements, and 100% unnecessary. Unfortunately, it's code like this that gives Fortran a bad name (reinforcing the perception that Fortran is an arcane and obsolete programming language). Anyone who is compiling this code is probably using a compiler that is at least Fortran 95 compatible. Who on earth is using straight up Fortran 77 compilers at this point? So why restrict such a useful library to a programming style that is so totally out of date? I think it is even probably affecting the efficiency of the code, since the example above required using a temporary array and a function call to do what can now be done with a (presumably much more efficient) intrinsic routine. It wouldn't even be that hard to convert this code to modern Fortran style. It's just low-level math routines, it doesn't have to be object-oriented or anything fancy like that. A while back, I wrote a little Python script to merge all the SOFA files into a single Fortran module (another innovation from the 1990s) so they can take advantage of the automatic interface checking that modules provide. There are also any number of tools out that could be used to automate the fixed to free-form conversion.
See also
Jan 27, 2018
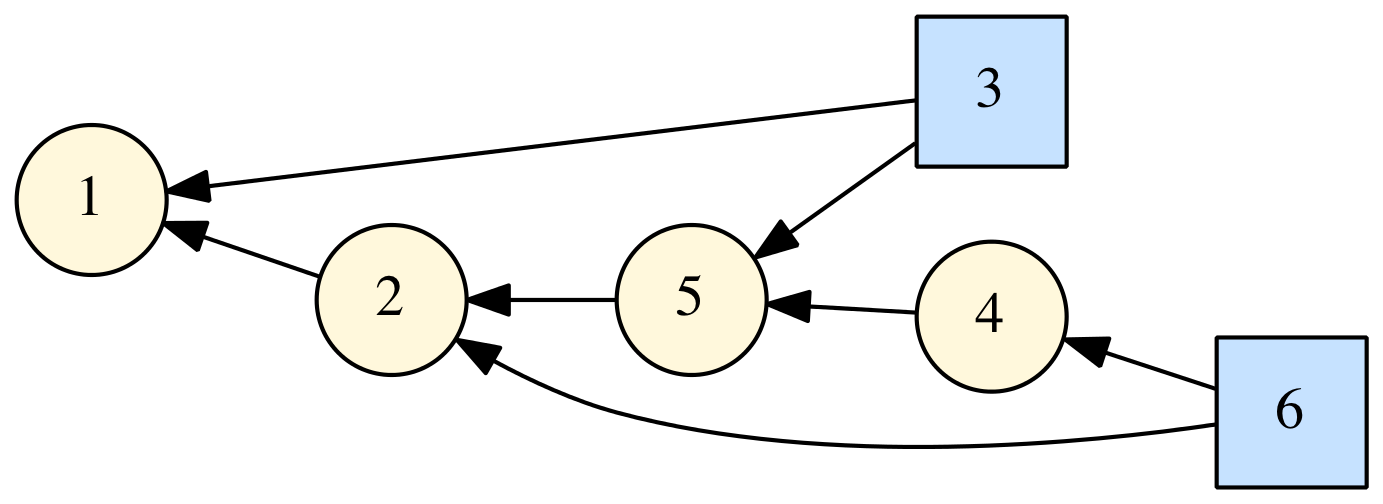
I released a new open source project on GitHub: DAGLIB, a modern Fortran library for manipulation of directed acyclic graphs (DAGs). This is based on some code I showed in a previous post. Right now, it's very basic, but you can use it to define DAGs, generate the topologically sorted order, and generate a "dot" file that can be used by GraphViz to visualize the DAG (such as the one shown at right).
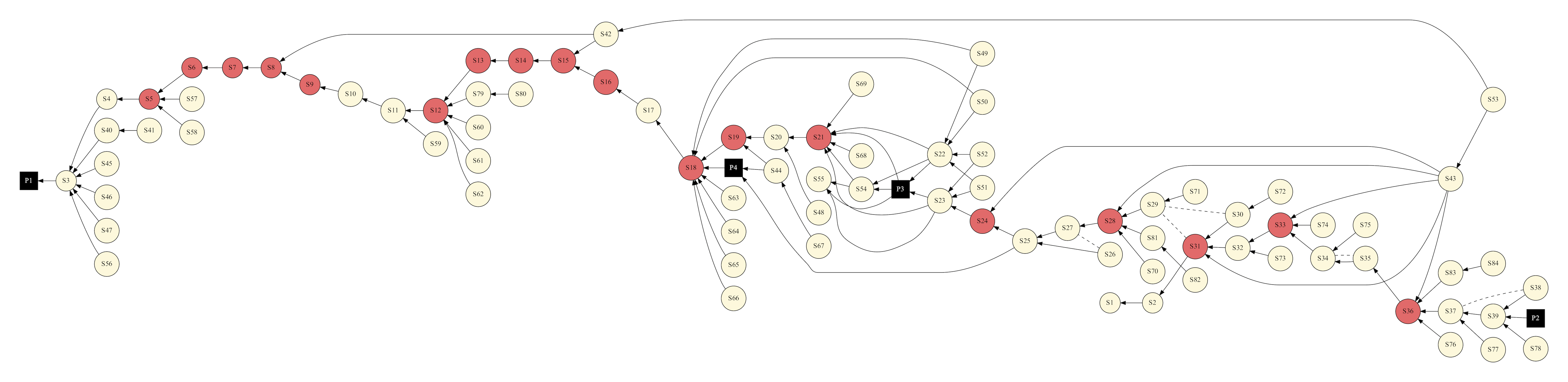
In my recent AIAA paper I showed the following DAG representing how we have designed the upcoming Orion EM-1 mission:

*During Exploration Mission-1, Orion will venture thousands of miles beyond the moon during an approximately three week mission. [NASA]*
In this case, the DAG represents the dependencies among different mission attributes (which represent maneuvers, coast phases, constraints, other algorithms, etc). To simulate the entire end-to-end mission, each element must be evaluated in the correct order such that all the dependencies are met. In this same paper, we also discuss other algorithms and their implementation in modern Fortran which may be familiar to readers of this blog.
See also
- J. Williams, R. D. Falck, and I. B. Beekman. "Application of Modern Fortran to Spacecraft Trajectory Design and Optimization", 2018 Space Flight Mechanics Meeting, AIAA SciTech Forum, (AIAA 2018-1451)
- (Modern?) Fortran directed graphs library [comp.lang.fortran] May 6, 2016
- JSON-Fortran GraphViz Example (how to generate a directed graph from a JSON structure), Apr 22, 2017
- The Ins and Outs of NASA’s First Launch of SLS and Orion, NASA, Nov. 27, 2015
Dec 10, 2017

The upcoming Fortran standard formerly known as Fortran 2015 has a new name: Fortran 2018. It was decided to change it in order to match the expected year of publication. This makes sense. The previous standard (Fortran 2008) was published in 2010.
Waiting for an updated Fortran standard is an exercise in Zen-like patience. Almost a decade after Fortran 2008, we'll get a fairly minor update to the core language. And it will be years after that before it's fully supported by any compiler that most users will have available (gfortran still doesn't have a bug-free implementation of all of Fortran 2008 or even 2003). Fortran was essentially reborn in the Fortran 2003 standard, which was an amazing update that brought Fortran into the modern world. It's a terrific programming language for scientific and technical computing. However, the limitations are all too clear and have been for a long time:
- We need better facilities for generic programming. It's impossible to do some things without having to duplicate code or use "tricks" like preprocessing or include files (see JSON-Fortran for examples).
- We need some kind of exception handling. Fortran does have a floating-point exception handling feature, but honestly, it's somewhat half-baked.
- We need a better implementation of strings. Allocatable strings (introduced in Fortran 2003) are great, but not enough, since they can't be used in all instances where strings are needed.
- We need the language to be generally less verbose. I'm tired to having to type multiple nested SELECT TYPE statements to do something that is a one liner in Python (sure I know Fortran will never be as succinct as Python, but some of the verbosity required for object-oriented Fortran is just perverse).
- We need any number of new features to make it easier to extend the language with third-party libraries (so we don't have to wait two decades for a feature we want).
- We also need the language development process to embrace a more open collaborative model using modern tools (Usenet is not the future). I guess the recent survey was unprecedented, but it's not enough.

Fortran is a programming language that needs a better PR department. Legacy Fortran codes are being rewritten in C++, Python, or even Julia. NASA frequently throws massive Fortran 77 libraries with decades of heritage (e.g., DPTRAJ/ODP, GTDS, SPICELIB) into the trash in order to rewrite it all from the ground up in C++, without ever considering Fortran 2003+ (or maybe not realizing it exists?). The information about modern Fortran on the internet is spotty at best, outdated, or downright wrong (what is the deal with REAL*8?). In popular consciousness Fortran is mostly a punchline (usually something to do with punchcards and your granddad). A language like Python (which was never designed for technical computing) is now seen by many as a superior solution for technical computing. Matlab refers to itself as "the only top programming language dedicated to mathematical and technical computing"! The Julia website lists somewhat misleading benchmarks than implies that C, Julia, and even Lua are faster than Fortran.
Now, get off my lawn, you kids!

See also
Sep 12, 2017

Intel has just released version 18 of the Intel Fortran Compiler (part of Intel Parallel Studio XE 2018). At long last, this release includes full support for the Fortran 2008 standard. The updates since the previous compiler release include:
COMPILER_OPTIONS and COMPILER_VERSION in ISO_FORTRAN_ENV- Complex arguments to trigonometric and hyperbolic intrinsic functions
FINDLOC intrinsic function- Optional argument
BACK in MAXLOC and MINLOC intrinsic functions
- Multiple type-bound procedures in a
PROCEDURE list
- Passing a non-pointer data item to a pointer dummy argument
- Polymorphic assignment with allocatable Left Hand Side (LHS)
- Allocatable components of recursive type and forward reference
- Data statement restrictions removed
In addition, the new release also includes support for all the features from "Technical Specification 29113 Further Interoperability with C", planned for inclusion in Fortran 2015. These include:
- Assumed type (
TYPE(*))
- Assumed rank (
DIMENSION(..))
- Relaxed restrictions on interoperable dummy arguments
ISO_Fortran_binding.h C include file for use by C code manipulating "C descriptors" used by Fortran
Hopefully, it won't take so long to get the compiler up to full Fortran 2015 compliance (see a previous post for a list of new Fortran 2015 features).
See also
