Oct 30, 2020

MPFUN2015 is a Fortran arbitrary precision library by David H. Bailey. An archive of the source code can be found on his website here (note that I also have a mirror of the source at GitHub if you want to peruse it). This library seems to be one of the few freely-available production-ready arbitrary precision Fortran libraries available that I can find, although arbitrary precision Fortran code has existed for quite a while (e.g., see Reference 1 from 1971). MPFUN2015 is pretty easy to use, but I think could use a little bit of modernization.
See also
- L. C. Maximon, Fortran Program for Arbitrary Precision Arithmetic, National Bureau of Standards, NBS 10-563, April 1, 1971.
- D. H. Bailey, A Thread-Safe Arbitrary Precision Computation Package (Full Documentation), August 23, 2019.
Apr 26, 2020

It's been about 8 months since my screed about things that were wrong with the Fortran ecosystem and standards committee. I got a lot of feedback from that post. It seems like a lot of people felt the same way. The funny thing is, it seems like some things are slowing beginning to change:
- A new GitHub repo was created for the community to work on proposals for the Fortran standard, to be discussed at committee meetings. This is unprecedented, and hopefully is just the beginning of putting the actual standard on GitHub for community inputs and editing.
- A new project: the Fortran standard library has begun to be developed on GitHub. This is for things that have been left out of the standard, and can be added to a library much quicker than the standard and compilers can be updated.
- A new website has appeared: fortran-lang.org as well as an associated project on GitHub. The goal of this is to be "the home" of Fortran on the internet. Something the two Fortran committee websites have never attempted to be. This site is community created (the contents are also on GitHub, so join us in helping to make it better).
These efforts are terrific, and serve as an online focus for the Fortran community, which up to this point has been mostly scattered and unorganized. The Fortran standards development process has hitherto been extremely opaque to the user community, so shining (still just a little bit of) light on that is good for everybody I think.
It has been clear for some time that some kind of change was needed in how the Fortran language is developed. In my view, the Fortran standards committee has failed spectacularly in the years since the release of Fortran 2003. Fortran 2003 was an amazing update to Fortran 95 that significantly expanded the utility of the language. Since then (for almost two decades) the focus has been on supercomputers and incremental improvements. The main pillar of Fortran language development seems to be to make absolutely sure that 50 year old spaghetti code still works without any modifications, even at the expense of correcting mistakes from decades ago that continually bedevil beginner Fortran programmers. In the meantime, Python (basically a scripting language used to wrap C/C++ libraries) has almost completely taken over scientific/technical computing, and amazing new languages have been created entirely from scratch (e.g., Chapel, Julia, Rust, Go, Swift) that all have made inroads into this field. All while the Fortran committee did very little to advance the language into new areas or make it more appealing to new programmers or people developing new libraries and codes. Fortran continues in some respects to hold its own on supercomputers and some massive legacy applications, but the writing is on the wall. The situation is dire, but I guess some of the committee seem to think nothing is wrong or they are in no hurry to do anything about Fortran's steady decline into irrelevance. According to a recent first-time attendee of the last committee meeting:
I spent last week at my first Fortran Standards Committee meeting. It was a pretty interesting experience. Everyone there was brilliant, and interested in trying to do a good job improving the language. And yet, it was still somehow very disfunctional.
everythingfunctional.wordpress.com

*Recent Meeting of the Fortran Standards Committee. (I kid because I love!)*
So I was very pleased to learn that Ondřej Čertík (@ondrejcertik) is running for chairman of the ISO Fortran Committee. Ondřej has been one of the main people spearheading all these new efforts. He also is the one behind LFortran, which looks to be one of the most innovative Fortran compilers in recent memory (actually moving Fortran just a little bit toward the direction of dynamic languages like Python, which is absolutely critical for getting new users onboard). Ondřej has published a platform which is fantastic. He has my total support (whatever that's worth!)
So, we'll see where all this goes. Hopefully things are improving. I encourage all Fortran users to support these new efforts, contribute to these new projects, and help with the website. Fortran is still a terrific language for numerical/scientific/technical computing. Getting the user community organized, improving the ecosystem, and improving the language standards process are only going to make it better in the long run.
Fun fact: the "F" Fortran logo shown above is based on the cover of the original IBM Fortran programmer's reference manual from 1956. Using the "WhatTheFont" feature at MyFonts.com, I determined that the font was Clarendon, or something very close to it. I created this icon in Inkscape some time ago in the original ugly brown color (e.g., it's the favicon for this website). Milan Curcic (@realmilancurcic) changed it to a nice purple and started using it on the fortran-lang.org website. I cleaned it up a bit and now SVG and PNG versions can be found here. I guess we'll use it until somebody comes up with something better.
See also
Dec 18, 2019

Intel has released version 19.1 the Intel Fortran Compiler (part of Intel Parallel Studio XE 2020). According to the release notes, the new version adds a lot of features from Fortran 2018:
- Enhancements to the IMPLICIT statement allow specifying that all external procedures must declared EXTERNAL
- Enhancements to the GENERIC statement permit it to be used to declare generic interfaces
- The locality of variables may now be specified on a DO CONCURRENT statement
- Enhancements to edit descriptor forms E, D, EN, ES, and G allow a field width of zero, analogous to the F edit descriptor
- The exponent width e in a data edit descriptor may now be zero, analogous to a field width of zero
- The RN edit descriptor now rounds to nearest as specified by Fortran 2018 and ISO/IEC/IEEE 60559:2011
- The EX edit descriptor allows for hexadecimal format output of floating point values. Hexadecimal format floating point values are allowed on input.
- SIZE= may be specified for non-advancing I/O
- The values for SIZE= and POS= in an INQUIRE statement for pending asynchronous operations have been standardized
- The value assigned to the RECL= specifier in an INQUIRE statement now has standardized values
- A new form of the intrinsic function CMPLX does not require the KIND= keyword if the first argument is type COMPLEX
- The arguments to the SIGN function may be of different kinds
- INTEGER and LOGICAL arguments to intrinsic procedures are no longer required to be of default kind
- The named constants STAT_FAILED_IMAGE and STAT_UNLOCKED_FAILED_IMAGE have been defined in the intrinsic
ISO_FORTRAN_ENV module
- The non-block DO statement and the arithmetic IF statement are now deleted in Fortran 2018.
- COMMON, EQUIVALENCE and BLOCKDATA statements are now obsolescent
- The labeled form of DO loops is now obsolescent
- Locality of variables in DO CONCURRENT constructs can now be declared on the DO CONCURRENT statement
- Specific names of intrinsic procedures are now obsolescent
- FAIL IMAGE statement allows debugging recovery code for failed images without having to wait for an actual image failure
- The named constants STAT_FAILED_IMAGE and STAT_UNLOCKED_FAILED_IMAGE have been defined in the intrinsic
ISO_FORTRAN_ENV module
- An optional argument STAT= has been added to ATOMIC_REF and ATOMIC_DEFINE intrinsic procedures
- Optional STAT= and ERRMSG= specifiers have been added to the MOVE_ALLOC intrinsic procedure, to image selectors, and to the CRITICAL statement and construct
- Atomic subroutines ATOMIC_ADD, ATOMIC_AND, ATOMIC_CAS, ATOMIC_FETCH_ADD, ATOMIC_FETCH_AND, ATOMIC_FETCH_OR, ATOMIC_FETCH_XOR, ATOMIC_OR, and ATOMIC_XOR have been implemented
- Collective subroutines CO_BROADCAST, CO_MAX, CO_MIN, CO_REDUCE, and CO_SUM have been implemented
- The SELECT RANK construct has been implemented allowing manipulation of assumed rank dummy arguments
- The compiler will now diagnose the use of nonstandard intrinsic procedures and modules as required by Fortran 2018
- Transformational intrinsic functions from the intrinsic modules ISO_C_BINDING, IEEE_ARITHMETIC, and IEEE_EXCEPTIONS are now allowed in specification expressions
- You can now specify the optional argument RADIX for the IEEE_GET_ROUNDING_MODE and IEEE_SET_ROUNDING_MODE intrinsic module procedures
- The optional ROUND argument has been added to the IEEE_RINT function in the intrinsic module IEEE_ARITHMETIC
- The intrinsic module IEEE_ARITHMETIC now includes the functions IEEE_FMA, IEEE_SIGN_BIT, IEEE_NEXT_UP and IEEE_NEXT_DOWN
- The intrinsic module procedures IEEE_MAX, IEEE_MIN, IEEE_MAX_MAG, and IEEE_MIN_MAG have been implemented
- The intrinsic module procedures IEEE_INT and IEEE_REAL have been implemented
- The intrinsic module IEEE_EXCEPTIONS now contains a new derived type, IEEE_MODES_TYPE, which can be used to save and restore the IEEE_MODES using the IEEE_GET_MODES and the IEEE_SET_MODES intrinsic module procedures
- A new rounding mode, IEEE_AWAY has been added
- SUBNORMAL is now synonymous with DENORMAL
- IEEE_QUIET_EQ, IEEE_QUIET_NE, IEEE_QUIET_LT, IEEE_QUIET_LE, IEEE_QUIET_GT, IEEE_QUIET_GE, IEEE_SIGNALING_EQ, IEEE_SIGNALING_NE, IEEE_SIGNALING_GT, IEEE_SIGNALING_GE, IEEE_SIGNALING_LT, and IEEE_SIGNALING_LE intrinsic module procedures have been implemented
The Intel Fortran Compiler has full support for the Fortran 2008 standard and includes most features from the Fortran 2018 standard.
See also
Oct 18, 2019
Just in case you find yourself needing to do some multidimensional data interpolation with modern Fortran:
- I just published a modernized version of REGRIDPACK, a library for "regriding" 1D-4D data sets using linear and spline interpolation. The original version of this library (which used to be called TLCPACK) was formerly available from the UCAR website, but it is now nowhere to be seen. It was a well-written library, and had the nice feature of being able to specify linear or spline interpolation independently for each dimension. My refactoring is simply an update of the old code to modern standards.
- I also recently added nearest neighbor interpolation to my Finterp library. So, now you can perform linear and nearest neighbor interpolation/extrapolation on 1D-6D data sets.
- My Bspline-Fortran library can also be used for interpolation/extrapolation of 1D-6D data sets using B-splines. This library is being used by several people for CFD work, it seems.
There are precious few modern Fortran libraries for other types of interpolation. Here are a couple:
- FOLLIA -- Fortran Library for Lagrange Interpolation
- curvefit -- A library for fitting functions to sets of data.
There are also any number of old school FORTRAN 77 codes out there that haven't been updated in decades, but still work fine for what they do, including:
- PCHIP -- Piecewise Cubic Hermite Interpolation Package from SLATEC.
- PPPACK -- Piecewise polynomial interpolation code from from A Practical Guide to Splines by C. de Boor.
- FITPACK -- a collection of FORTRAN programs for curve and surface fitting with splines and tensor product splines.
See also
Sep 15, 2019
I'm working on a modern Fortran version of the simulated annealing optimization algorithm, using this code as a starting point. There is a Fortran 90 version here, but this seems to be mostly just a straightforward conversion of the original code to free-form source formatting. I have in mind a more thorough modernization and the addition of some new features that I need.
Refactoring old Fortran code is always fun. Consider the following snippet:
C Check termination criteria.
QUIT = .FALSE.
FSTAR(1) = F
IF ((FOPT - FSTAR(1)) .LE. EPS) QUIT = .TRUE.
DO 410, I = 1, NEPS
IF (ABS(F - FSTAR(I)) .GT. EPS) QUIT = .FALSE.
410 CONTINUE
This can be greatly simplified to:
! check termination criteria.
fstar(1) = f
quit = ((fopt-f)<=eps) .and. (all(abs(f-fstar)<=eps)
Note that we are using some of the vector features of modern Fortran to remove the loop. Consider also this function in the original code:
FUNCTION EXPREP(RDUM)
C This function replaces exp to avoid under- and overflows and is
C designed for IBM 370 type machines. It may be necessary to modify
C it for other machines. Note that the maximum and minimum values of
C EXPREP are such that they has no effect on the algorithm.
DOUBLE PRECISION RDUM, EXPREP
IF (RDUM .GT. 174.) THEN
EXPREP = 3.69D+75
ELSE IF (RDUM .LT. -180.) THEN
EXPREP = 0.0
ELSE
EXPREP = EXP(RDUM)
END IF
RETURN
END
It is somewhat disturbing that the comments mention IBM 370 machines. This routine is unchanged in the f90 version. However, these numeric values are no longer correct for modern hardware. Using modern Fortran, we can write a totally portable version of this routine like so:
pure function exprep(x) result(f)
use, intrinsic :: ieee_exceptions
implicit none
real(dp), intent(in) :: x
real(dp) :: f
logical,dimension(2) :: flags
type(ieee_flag_type),parameter,dimension(2) :: out_of_range = [ieee_overflow,ieee_underflow]
call ieee_set_halting_mode(out_of_range,.false.)
f = exp(x)
call ieee_get_flag(out_of_range,flags)
if (any(flags)) then
call ieee_set_flag(out_of_range,.false.)
if (flags(1)) then
f = huge(1.0_dp)
else
f = 0.0_dp
end if
end if
end function exprep
This new version is entirely portable and works for any real kind. It contains no magic numbers and uses the intrinsic IEEE exceptions module of modern Fortran to protect against overflow and underflow, and the huge() intrinsic to return the largest real(dp) number.
So, stay tuned...
See also
- S. Kirkpatrick, C. D. Gelatt Jr., M. P. Vecchi, "Optimization by Simulated Annealing", Science 13 May 1983, Vol. 220, Issue 4598, pp. 671-680
- W. L. Goffe, SIMANN: A Global Optimization Algorithm using Simulated Annealing, Studies in Nonlinear Dynamics & Econometrics, De Gruyter, vol. 1(3), pages 1-9, October 1996.
- Original simann.f source code [Netlib]
Aug 03, 2019

It amuses me somewhat to see the push to get people to stop using Python 2. Python 2 was sort of replaced with Python 3 in 2008. However, Python 3 broke backward compatibility, and Python 2 continued to be supported and even developed (some of the Python 3 features have even been backported to Python 2 which is somewhat bizarre). However, the official Python maintainers have declared January 1st, 2020 to be the end of life for Python 2. However, many Linux distos (as well as MacOS) still include Python 2 as the default.
The situation with Fortran is significantly different. You can still get (even purchase) a Fortran compiler that can compile obsolescent FORTRAN 77 written 40 years ago. A lot of people haven't gotten the memo that Fortran has moved on. Not a day goes by where there isn't a StackOverflow question from somebody about some godawful FORTRAN 77 code that they can't figure out how to get working. So, I wonder how successful this effort will be with Python. Will there still be Python 2 holdouts 30 years from now? Of course, the Python community is significantly different from the Fortran community (to whatever extent Fortran could be said to even have a community). The Python implementation is open source so people are free in theory to just fork it and continue to update it. But, as the official source dries up I suspect eventually people will just move on.
There is basically no one centralized place for Fortran users to learn about Fortran, download Fortran, work on or even comment on changes to Fortran, or anything else really. Backward compatibility is actually one of the major strengths of Fortran, but there just isn't anyone to tell you to move on. Many of the major Fortran libraries freely available on the internet are still, in 2018, written in Fortran 77 (see NetLib, where Fortran codes go to die). There is also SOFA and SPICELIB (two libraries still being developed in Fortran 77 for some reason). There is LAPACK, probably the most visible FORTRAN 77 library. It turns out, you can't even link LAPACK and SPICELIB in the same program anymore, because both now have a routine called DPSTRF! If these libraries weren't using this depreciated source form and were actually using Fortran 90 modules (or god forbid, Fortran 2008 submodules) we wouldn't have this problem. Nobody should be publishing a Fortran library at this point that is just a pile of subroutines. And yet, they do.
Sure, there is a Fortran standards committee. But they write the standard and don't do much else. There isn't any official website that serves as any kind of central location to learn about the language or download any compilers. There is no nonprofit "Fortran Foundation". There isn't even a Fortran logo. What we basically have is a few compiler vendors such as NAG, Intel, PGI, as well as the open source gfortran developers, each with their own websites and their own schedules. Even the C++ language (another ISO standard language) has a GitHub site and even an actual homepage. The Fortran committee website is extremely underwhelming, and is basically just a list of links to plain text files that have meeting minutes and some other documents. The odds of a new user even finding this site are pretty slim (and of course, there really isn't anything useful here anyway). The Fortran standards process seems very opaque (I guess it involves infrequent meetings and typing up plain text files).
In many ways, the standards committee has failed the user base. The slowness of the language development process, the refusal to adopt modern practices of collaboration, and the refusal to address major shortcomings of the language has allowed other languages to overtake Fortran in the fields it was once dominant. In fields such as machine learning, one of the major computational activities of modern times, there is no significant presence of Fortran. The committee has given us incremental, somewhat half-baked features that don't really solve real-world problems in any kind of satisfactory manner (like ISO_VARYING_STRING, parametrized derived types, user-defined IO, floating point exceptions). While shortcomings from decades ago are left unaddressed (lack of a useful mechanism for generic programming, lack of access to the file system, no intrinsic high-level classes for dynamic structures such as stacks and queues, no useful varying string class, a non-standard module file format that is a constant source of annoyance for both users and library developers, even the lack of a standardized file extension for Fortran, which leads to nonsense like .f90, .f03, .f08, .f18? being used). It's incredible but true that the Fortran standard doesn't actually define a file extension to be used for Fortran. One of the respondents to a recent survey on Fortran language development had this to say:
The standard committee is too inbred with compiler developers who only see the language from the inside out and lacking in users who know what features they need for their particular application space.
Amazing libraries in the scientific/technical/numerical domain are being written in other programming languages. DifferentialEquations.jl is the type of high-quality math-oriented library that no one is writing anymore in Fortran (indeed it makes use of features of Julia that aren't even possible in Fortran). This article about using Julia as a differentiable language is the sort of thinking we desperately need in the Fortran world. Not more excuses about why fundamental changes can't be made to Fortran for fear of breaking somebody's 60 year old spaghetti code.
See also
- Ben James, Stop Using Python 2: What you Need to Know About Python 3, August 15, 2018 [hackaday.com]
- https://pythonclock.org
- PEP 373 -- Python 2.7 Release Schedule
- M. Innes, et. al., Building a Language and Compiler for Machine Learning, Dec 3, 2018 [julialang.org]
- Some ideas for Fortran, from a newbies perspective, July 22, 2019 [comp.lang.fortran]
May 04, 2019

Gfortran 9.1 (part of GCC) has been released. Apparently this is a significant GCC release with a "huge number of improvements" including a new D language component. Of course, the Fortran updates are a little more modest. According to the release notes, the updates are:
- Asynchronous I/O is now fully supported [Fortran 2003].
- The
BACK argument for MINLOC and MAXLOC has been implemented [Fortran 2008].
- The
FINDLOC intrinsic function has been implemented [Fortran 2008].
- The
IS_CONTIGUOUS intrinsic function has been implemented [Fortran 2008].
- Direct access to the real and imaginary parts of a complex variable via
c%re and c%im has been implemented [Fortran 2008].
- Type parameter inquiry via
str%len and a%kind has been implemented [Fortran 2008].
- C descriptors and the
ISO_Fortran_binding.h source file have been implemented [Fortran 2018].
- The
MAX and MIN intrinsics are no longer guaranteed to return any particular value in case one of the arguments is NaN.
- A new command-line option
-fdec-include, has been added as an extension for compatibility with legacy code using some non-standard behavior from the old DEC compiler.
- A new
BUILTIN directive, has been added. The purpose of the directive is to provide an API between the GCC compiler and the GNU C Library which would define vector implementations of math routines.
In addition, the release includes a bunch of bug fixes. Gfortran has more-or-less complete support for Fortran 2003, and only a couple things missing from Fortran 2008. There is a ways to go for full Fortran 2018 support. Gfortran is maintained by a very small number of volunteers, and their hard work is greatly appreciated!
See also
Mar 23, 2019

There are now at least five open source Fortran compilers (in various stages of completion) that are based on LLVM:
- Flang -- Original attempt (possibly defunct?) by the LLVM Team at the University of Illinois at Urbana-Champaign.
- Flang -- The first attempt by NVIDIA/PGI. It's some kind of open-sourced version of their commercial compiler being funded by Lawrence Livermore, Sandia and Los Alamos National Laboratories. See previous post when this was first announced in 2015.
- f18 -- The second (modernized) attempt by NVIDIA/PGI, built from the ground up. Intended to be a replacement for the previous one.
- DragonEgg -- This one uses LLVM as a GCC backend. Also seems to be defunct, the website says it only works with the very old GCC 4.6.
- lfortran -- This one is very interesting, since it isn't just a run of the mill Fortran compiler, it extends the language a little bit to include a REPL and some other great ideas. This one seems to have some connection to Los Alamos National Laboratory as well, but doesn't appear to be related to the NVIDIA Flang one.
None of these really seem to be finished yet. Hopefully, one or more will achieve full Fortran 2018 compliance and be good enough for production work. I'm particular interested to see how lfortran matures. In recent years, LLVM has taken the compiler world by storm, and it will be nice to see Fortran get in on the action.
References
Dec 10, 2018
I came across this old NASA document from 1963, where a cross product subroutine is defined in Fortran (based on some of the other routines given, it looks like they were using FORTRAN II):

A cross product function is always a necessary procedure in any orbital mechanics simulation (for example when computing the angular momentum vector \(\mathbf{h} = \mathbf{r} \times \mathbf{v}\)). The interesting thing is that this subroutine will still compile today with any Fortran compiler. Of course, there are a few features used here that are deemed obsolescent in modern Fortran (fixed-form source, implicit typing, and the DIMENSION statement). Also it is using single precision reals (which no one uses anymore in this field). A modernized version would look something like this:
subroutine cross(a,b,c)
implicit none
real(wp),dimension(3),intent(in) :: a,b
real(wp),dimension(3),intent(out) :: c
c(1) = a(2)*b(3)-a(3)*b(2)
c(2) = a(3)*b(1)-a(1)*b(3)
c(3) = a(1)*b(2)-a(2)*b(1)
end subroutine cross
But, basically, except for declaring the real kind, it does exactly the same thing as the one from 1963. The modern routine would presumably be put in a module (in which the WP kind parameter is accessible), for example, a vector utilities module. While a subroutine is perfectly acceptable for this case, my preference would be to use a function like so:
pure function cross(a,b) result(c)
implicit none
real(wp),dimension(3),intent(in) :: a,b
real(wp),dimension(3) :: c
c(1) = a(2)*b(3)-a(3)*b(2)
c(2) = a(3)*b(1)-a(1)*b(3)
c(3) = a(1)*b(2)-a(2)*b(1)
end function cross
This one is a function that return a \(\mathrm{3} \times \mathrm{1}\) vector, and is explicitly declared to be PURE (which can allow for more aggressive code optimizations from the compiler).
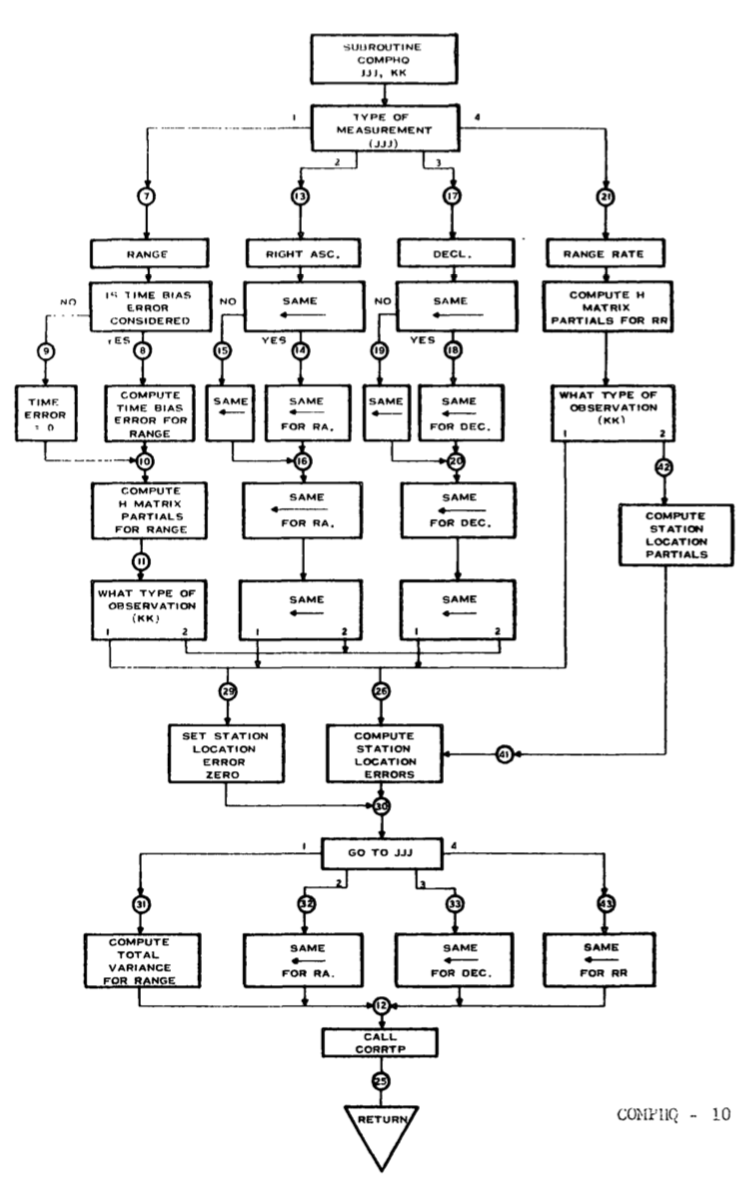
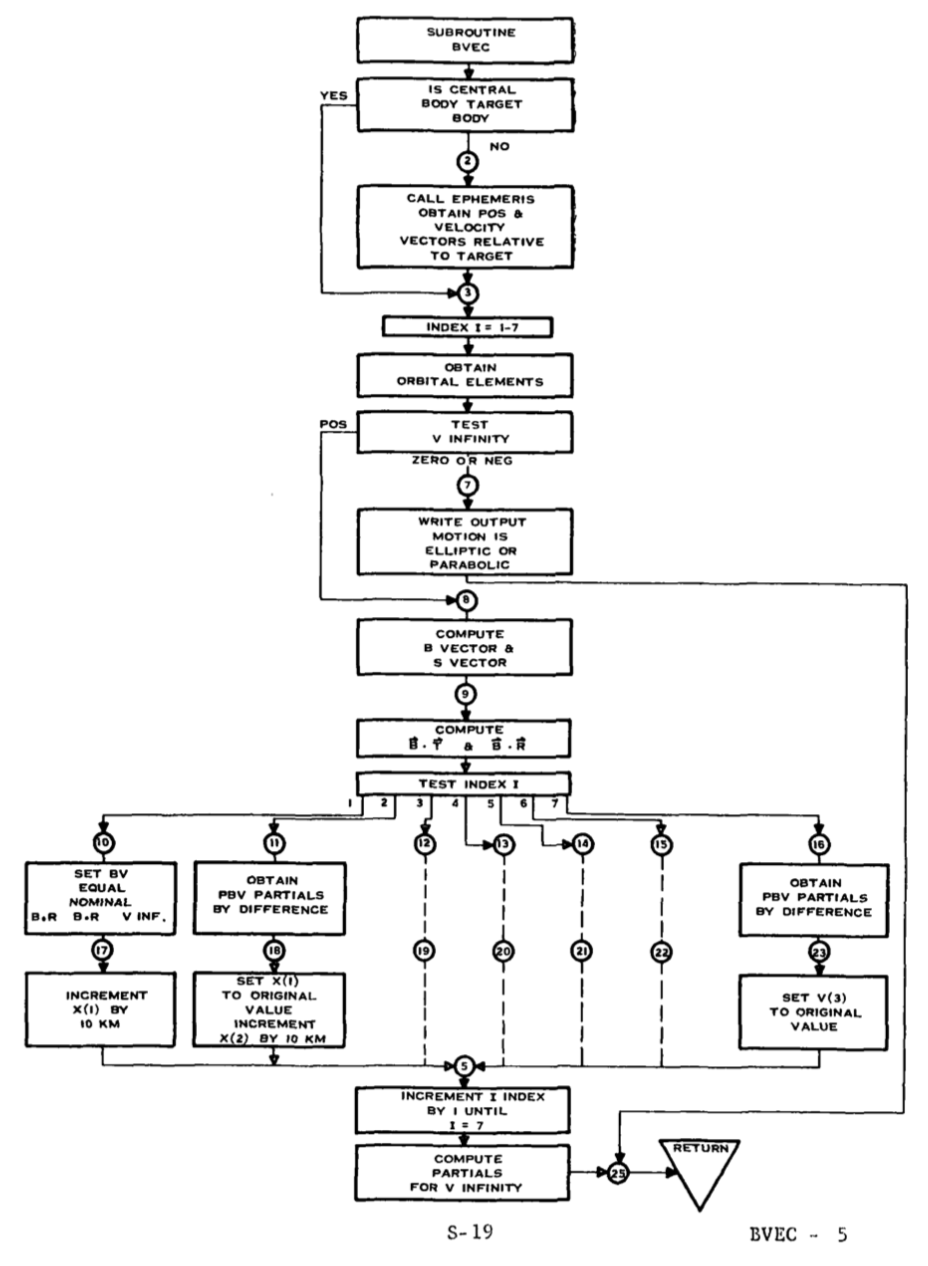
This document, which is the programmer's manual for an interplanetary error propagation program, contains a lot of other Fortran gems. It also has some awesome old school flow charts:
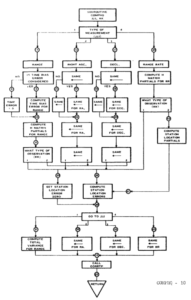
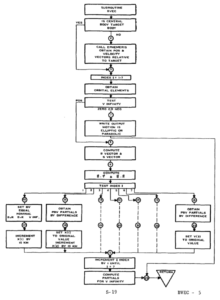
See also
Dec 03, 2018

Fortran 2018 (ISO/IEC 1539:2018) has been officially published by the ISO, so it is now the official Fortran standard, replacing the nearly decade-old Fortran 2008 (which was actually published in 2010). Since this is a copyrighted ISO document, you can't actually view it online for free, but you can view the final draft which is basically the same thing.
The final draft document for Fortran 2018 is 630 pages. By contrast, the original Fortran Programmer's Reference Manual, produced by IBM in 1956, was only 51 pages. The language has certainly changed a lot in 62 years. Modern Fortran is still the programming language of choice for many of us solving very large and complex computational problems in science and engineering. It is the only scientific programming language that does not compromise on speed in order to provide dynamic typing, a REPL, JIT, or whatever the latest computing fad is. It is the only scientific programming language that is an international standard. It is the only scientific programming language that has multiple complete implementations from different vendors. It has a far superior array and matrix syntax than C-based languages. Its syntax is straightforward and can be mastered by non-professional programmers. It's hard to write slow code in Fortran, even if you barely know what you're doing. Modern Fortran is object-oriented and also provides a standardized interoperability with C-based languages (nowadays this is quite useful for interfacing with Python). Fortran-based tools are used by NASA to design and optimize the trajectories of interplanetary spacecraft. The next generation of crewed spacecraft missions are being designed with Fortran-based tools.
Now, Fortran is not without its flaws (perhaps I will write a post one day on the things I don't like about Fortran), but it is still very good at doing what it was designed to do. Improvements added in each new revision continue to breathe new life into this venerable programming language.
See also