Aug 24, 2014

The Computus is the algorithm for the calculation of the date of Easter. The following is a simple Fortran subroutine of the Computus, using the "Meeus/Jones/Butcher" Gregorian Easter algorithm. Note that this subroutine makes use of Fortran integer division.
subroutine easter(year,month,day)
!Compute the date of Gregorian Easter,
! using the "Meeus/Jones/Butcher" algorithm
implicit none
integer,intent(in) :: year
integer,intent(out) :: month,day
integer :: a,b,c,d,e,f,g,h,i,k,l,m
a = mod(year,19)
b = year/100
c = mod(year,100)
d = b/4
e = mod(b,4)
f = (b+8)/25
g = (b-f+1)/3
h = mod((19*a+b-d-g+15),30)
i = c/4
k = mod(c,4)
l = mod((32+2*e+2*i-h-k),7)
m = (a+11*h+22*l)/451
month = (h+l-7*m+114)/31
day = mod(h+l-7*m+114,31)+1
end subroutine easter
The sequence of dates repeat themselves over a cycle of 5,700,000 years. The following histogram shows the percentage occurrence of each date (from March 22nd to April 25th), over the entire cycle:
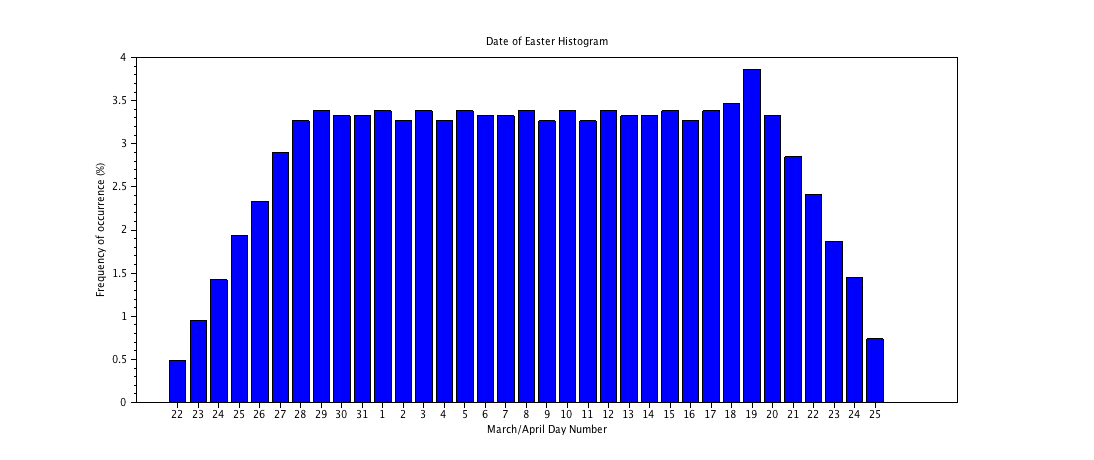
See also
- D. Steel, "Marking Time: The Epic Quest to Invent the Perfect Calendar", Wiley, 1999.
- J. R. Stockton, "The Calculation of Easter Sunday after the Book of Common Prayer of the Church of England".
Aug 10, 2014
Old style fixed-form Fortran code (commonly called FORTRAN 77 style) was replaced by free-form style in 1991 with the introduction of the Fortran 90 standard. In spite of this, fixed-form code can still be found in legacy projects, and there are some people who still write it for whatever reason (possibly unaware that a better format exists). There are also a large number of high-quality legacy fixed-form code libraries from back in the day that still work great. All modern Fortran compilers accept both fixed and free-form code, but there is very little reason for new fixed-form code to be written today. Also, it is often convenient to convert old-style code to free-format if it is going to be maintained or upgraded by a programmer in the present day. The following list provides links to several free tools to convert fixed-form code to free-form code (there are also several commercially-available solutions):
See also
- Source Form Just Wants to be Free
- Modernizing Old Fortran
Jul 29, 2014
Yes, now animated GIFs can be created using only Fortran code. I present FGIF, now on GitHub. It is a modified and updated version of the public domain code found on the Fortran Wiki. It was used to create the image shown here (which is an example of a circle illusion).
For more information on the GIF format, see:
It was interesting to discover that animated GIFs are actually a Netscape extension to the GIF file format. If you open any animated GIF in a hex editor, you will find the string "NETSCAPE2.0".
Jul 24, 2014
JPL just released a new version of the SPICE Toolkit (N65). According to the What's New page, changes include:
- support for some new environments and termination of some old environments
- new Geometry Finder (GF) interfaces -- illumination angle search, phase angle search, user-defined binary quantity search
- new high-level SPK APIs allowing one to specify the observer or target as a location with a constant position and velocity rather than as an ephemeris object
- new high-level APIs that check for occultation and in-Field-Of-View (FOV) conditions
- new high-level illumination angle routines
- new high-level reference frame transformation routine
- new high-level coordinate system transformation routine for states
- many Icy and Mice APIs that were formerly available only in SPICELIB and CSPICE
- new data types: SPK (19, 20, 21), PCK (20), and CK (6)
- performance improvements in the range of 10-50 percent for some types of use
- ability to load up to 5000 kernels
- increased buffers in the POOL and in SPK and CK segment search subsystems
- new built-in body name/ID code mappings and body-fixed reference frames
- a significant upgrade of utility SPKDIFF including the ability to sample SPK data
- updates to other toolkit utilities -- BRIEF, CKBRIEF, FRMDIFF, MKSPK, MSOPCK
- bug fixes in Toolkit and utility programs
Jul 23, 2014
I just tagged the 1.0.0 release of json-fortran. You're welcome, interwebs.
Jul 21, 2014
Rodrigues' rotation formula can be used to rotate a vector \(\mathbf{v}\) a specified angle \(\theta\) about a specified rotation axis \(\mathbf{k}\):
$$
\mathbf{v}_\mathrm{rot} = \mathbf{v} \cos\theta + (\hat{\mathbf{k}} \times \mathbf{v})\sin\theta
+ \hat{\mathbf{k}} (\hat{\mathbf{k}} \cdot \mathbf{v}) (1 - \cos\theta)
$$
A Fortran routine to accomplish this (taken from the vector module in the Fortran Astrodynamics Toolkit) is:
subroutine rodrigues_rotation(v,k,theta,vrot)
implicit none
real(wp),dimension(3),intent(in) :: v !vector to rotate
real(wp),dimension(3),intent(in) :: k !rotation axis
real(wp),intent(in) :: theta !rotation angle [rad]
real(wp),dimension(3),intent(out) :: vrot !result
real(wp),dimension(3) :: khat
real(wp) :: ct,st
ct = cos(theta)
st = sin(theta)
khat = unit(k)
vrot = v*ct + cross(khat,v)*st + &
khat*dot_product(khat,v)*(one-ct)
end subroutine rodrigues_rotation
This operation can also be converted into a rotation matrix, using the equation:
$$
\mathbf{R} = \mathbf{I} + [\hat{\mathbf{k}}\times]\sin \theta + [\hat{\mathbf{k}}\times] [\hat{\mathbf{k}}\times](1-\cos \theta)$$
Where the matrix \([\hat{\mathbf{k}}\times]\) is the skew-symmetric cross-product matrix and \(\mathbf{v}_\mathrm{rot} = \mathbf{R} \mathbf{v}\).
References
- Rotation Formula [Mathworld]
- Rodrigues' Rotation Formula [Mathworld]
- Do We Really Need Quaternions? [Gamedev.net]
- R. T. Savely, B. F. Cockrell, and S. Pines, "Apollo Experience Report -- Onboard Navigational and Alignment Software", NASA TN D-6741, March 1972. See the Appendix by P. F. Flanagan and S. Pines, "An Efficient Method for Cartesian Coordinate Transformations".
Jul 20, 2014
GCC 4.9.1 has been released. The big news for Fortran users is that OpenMP 4.0 is now supported in gfortran.
Jul 13, 2014
I'm starting a new project on GitHub: the Fortran Astrodynamics Toolkit. Hardly anyone is developing open source orbital mechanics software for modern Fortran, so the time has come. Most of the code from this blog will eventually find its way there. My goal is to include modern Fortran implementations of all the standard orbital mechanics algorithms such as:
- Lambert solvers
- Kepler propagators
- ODE solvers (Runge-Kutta, Nyström, Adams)
- Orbital element conversions
Then we'll see where it goes from there. The code will be released under a permissive BSD style license.
Jul 08, 2014
Here is a simple Fortran subroutine to return only the unique values in a vector (inspired by Matlab's unique function). Note, this implementation is for integer arrays, but could easily be modified for any type. This code is not particularly optimized, so there may be a more efficient way to do it. It does demonstrate Fortran array transformational functions such as pack and count. Note that to duplicate the Matlab function, the output array must also be sorted.
subroutine unique(vec,vec_unique)
! Return only the unique values from vec.
implicit none
integer,dimension(:),intent(in) :: vec
integer,dimension(:),allocatable,intent(out) :: vec_unique
integer :: i,num
logical,dimension(size(vec)) :: mask
mask = .false.
do i=1,size(vec)
!count the number of occurrences of this element:
num = count( vec(i)==vec )
if (num==1) then
!there is only one, flag it:
mask(i) = .true.
else
!flag this value only if it hasn't already been flagged:
if (.not. any(vec(i)==vec .and. mask) ) mask(i) = .true.
end if
end do
!return only flagged elements:
allocate( vec_unique(count(mask)) )
vec_unique = pack( vec, mask )
!if you also need it sorted, then do so.
! For example, with slatec routine:
!call ISORT (vec_unique, [0], size(vec_unique), 1)
end subroutine unique
Jul 08, 2014
I agree with everything said in this article: My Corner of the World: C++ vs Fortran. I especially like the bit contrasting someone trying to learn C++ for the first time in order to do some basic linear algebra (like a matrix multiplication). Of course, in Fortran, this is a built-in part of the language:
matrix_c = matmul(matrix_a, matrix_b)
Whereas, for C++:
The bare minimum for doing the same exercise in C++ is that you have to get your hands on a library that does what you want. So you have to know about the existence of Eigen or another library. Then you have to figure out how to call it. Then you have to figure out how to link to an external library. And the documentation is probably not that helpful. There are friendly C++ users for sure. It's just that you won't have a clue what they're telling you to do. They'll be telling you to set up a makefile. They'll be recommending that you look at Boost and talking about how great it is and you'll be all WTF.
And before you use that C++ library, are you really sure you won't end up with a memory leak? Do you even know what a memory leak is?
