May 15, 2016

The SLATEC Common Mathematical Library (CML) is written in FORTRAN 77 and contains over 1400 general purpose mathematical and statistical routines. SLATEC is an acronym for the "Sandia, Los Alamos, Air Force Weapons Laboratory Technical Exchange Committee", an organization formed in 1974 by the computer centers of these organizations. In 1977, it was decided to build a FORTRAN library to provide portable, non-proprietary, mathematical software for member sites' supercomputers. Version 1.0 of the CML was released in April 1982.
An example SLATEC routine is shown below, which computes the inverse hyperbolic cosine:
*DECK ACOSH
FUNCTION ACOSH (X)
C***BEGIN PROLOGUE ACOSH
C***PURPOSE Compute the arc hyperbolic cosine.
C***LIBRARY SLATEC (FNLIB)
C***CATEGORY C4C
C***TYPE SINGLE PRECISION (ACOSH-S, DACOSH-D, CACOSH-C)
C***KEYWORDS ACOSH, ARC HYPERBOLIC COSINE, ELEMENTARY FUNCTIONS, FNLIB,
C INVERSE HYPERBOLIC COSINE
C***AUTHOR Fullerton, W., (LANL)
C***DESCRIPTION
C
C ACOSH(X) computes the arc hyperbolic cosine of X.
C
C***REFERENCES (NONE)
C***ROUTINES CALLED R1MACH, XERMSG
C***REVISION HISTORY (YYMMDD)
C 770401 DATE WRITTEN
C 890531 Changed all specific intrinsics to generic. (WRB)
C 890531 REVISION DATE from Version 3.2
C 891214 Prologue converted to Version 4.0 format. (BAB)
C 900315 CALLs to XERROR changed to CALLs to XERMSG. (THJ)
C 900326 Removed duplicate information from DESCRIPTION section.
C (WRB)
C***END PROLOGUE ACOSH
SAVE ALN2,XMAX
DATA ALN2 / 0.6931471805 5994530942E0/
DATA XMAX /0./
C***FIRST EXECUTABLE STATEMENT ACOSH
IF (XMAX.EQ.0.) XMAX = 1.0/SQRT(R1MACH(3))
C
IF (X .LT. 1.0) CALL XERMSG ('SLATEC', 'ACOSH', 'X LESS THAN 1',
+ 1, 2)
C
IF (X.LT.XMAX) ACOSH = LOG (X + SQRT(X*X-1.0))
IF (X.GE.XMAX) ACOSH = ALN2 + LOG(X)
C
RETURN
END
Of course, this routine is full of nonsense from the point of view of a modern Fortran programmer (fixed-form source, implicitly typed variables, SAVE and DATA statements, constants computed at run time rather than compile time, hard-coding of the numeric value of ln(2), etc.). And you don't even want to know what's happening in the R1MACH() function. A modern version would look something like this:
pure elemental function acosh(x) result(acoshx)
!! arc hyperbolic cosine
use iso_fortran_env, only: wp => real64
implicit none
real(wp),intent(in) :: x
real(wp) :: acoshx
real(wp),parameter :: aln2 = &
log(2.0_wp)
real(wp),parameter :: r1mach3 = &
real(radix(1.0_wp),wp)**(-digits(1.0_wp)) !! largest relative spacing
real(wp),parameter :: xmax = &
1.0_wp/sqrt(r1mach3)
if ( x<1.0_wp ) then
error stop 'slatec : acosh : x less than 1'
else
if ( x<xmax ) then
acoshx = log(x + sqrt(x*x - 1.0_wp))
else
acoshx = aln2 + log(x)
end if
end if
end function acosh
Of course, the point is moot, since ACOSH() is now an intrinsic function in Fortran 2008, so we don't need either of these anymore. Unfortunately, like many great Fortran codes, SLATEC has been frozen in amber since the early 1990's. It does contain a great many gems, however, and any deficiencies in the original Fortran 77 code can be easily remedied using modern Fortran standards. See also, for example, my own DDEABM project, which is a complete refactoring and upgrade of the Adams-Bashforth-Moulton ODE solver from SLATEC.
The GNU Scientific Library was started in 1996 to be a "modern version of SLATEC". Of course, rather than refactoring into modern Fortran (Fortran 90 had been published several years earlier, but I believe it was some time before a free compiler was available) they decided to start over in C. There's now even a Fortran interface to GSL (so now we can use a Fortran wrapper to call a C function that replaced a Fortran function that worked perfectly well to begin with!) The original SLATEC was a public domain work of the US government, and so can be used without restrictions in free or proprietary applications, but GSL is of course, GPL, so you're out of luck if you are unable to accept the ~~restrictions~~ (I mean freedom) of that license.
Note that John Burkardt has produced a version of SLATEC translated to free-form source. The license for this modified version is unclear. Many of his other codes are LGPL (still more restrictive than the original public domain codes). It's not a full refactoring, either. The codes still contain non-standard extensions and obsolescent and now-unnecessary features such as COMMON blocks. What we really need is a full modern refactoring of SLATEC (and other unmaintained codes like the NIST CMLIB and NSWC, etc.)
References
- Fong, Kirby W., Jefferson, Thomas H., Suyehiro, Tokihiko, Walton, Lee, "Guide to the SLATEC Common Mathematical Library", July 1993.
- SLATEC source code at Netlib.
May 12, 2016

GitHub announced yesterday that all of their paid plans now include unlimited private repositories. They've also simplified their pricing scheme, so now there is only one paid plan for individuals for \$7 per month. This now includes unlimited private repositories, and these can include collaborators.
All of my open source projects are hosted on GitHub. It's been a great way to share and collaborate on code. Now it looks like it's even better for working on stuff that you might not want to share.
Be sure to also check out the Fortran F/OSS programmers group.
May 09, 2016

JSON-Fortran 5.0 is out. This release finally brings thread-safety to the library. Note that it does break backward compatibility with previous versions, but hopefully it isn't too much trouble to modify your code to be compatible with the new release. I've provided a short guide describing what you need to do.
JSON-Fortran is a Fortran 2008 JSON API, based on an earlier project called FSON (which was written in Fortran 95). FSON was not thread-safe, and so neither was JSON-Fortran at first. This was mainly due to the use of various global settings, and global variables used during parsing and for keeping track of errors.
In the transition from FSON to JSON-Fortran, I added a high-level json_file class that is used to do a lot of common operations (e.g. open a JSON file and read data from it). However, building a JSON structure from scratch is done using lower-level json_value pointers. In the 5.0 release, there is a new factory class called json_core that is now the interface for manipulating json_value variables. Thus, each instance of this class can exist independently of any others (each with potentially different settings), and so provides thread-safe operation and error handling. The json_file class simply contains an instance of json_core, which contains all the variables and settings that were formerly global to the entire module.
A very simple example of the pre-5.0 usage would be:
program test
use json_module
implicit none
type(json_file) :: json
integer :: ival
character(len=:),allocatable :: cval
logical :: found
call json_initialize()
call json%load_file(filename='myfile.json')
call json%print_file() !print to the console
call json%get('var.i',ival,found)
call json%get('var.c',cval,found)
call json%destroy()
end program test
For 5.0, all you have to do is change:
to
and you're done. All global variables have been eliminated and the only entities that are user-accessible are three public types and their methods.
There are also a ton of other new features in JSON-Fortran 5.0, including new APIs, such as:
json_core%validate() -- test the validity of a JSON structure (i.e., a json_value linked list).json_core%is_child_of() -- test if one json_value is a child of another.json_core%swap() -- swap two json_value elements in a JSON structure (this may be useful for sorting purposes).json_core%rename() -- rename a json_value variable in a JSON structure.
And new settings (set during the call to initialize()) such as:
- Trailing spaces can now be significant for name comparisons.
- Name comparisons can now be case sensitive or case insensitive.
- Can enable strict type checking to avoid automatic conversion of numeric data (say, integer to double) when getting data from a JSON structure.
- Can set the number of spaces for indenting when writing JSON data to a file.
See also
Apr 28, 2016

Gfortran 6.1 (part of GCC) has been released. The release notes don't say much with respect to Fortran:
- The
MATMUL intrinsic is now inlined for straightforward cases if front-end optimization is active. The maximum size for inlining can be set to n with the -finline-matmul-limit=n option and turned off with -finline-matmul-llimit=0.
- The
-Wconversion-extra option will warn about REAL constants which have excess precision for their kind.
- The
-Winteger-division option has been added, which warns about divisions of integer constants which are truncated. This option is included in -Wall by default.
But, apparently, this version includes some nice updates, including support for Fortran 2008 submodules, Fortran 2015 Coarray events, as well as bug fixes for deferred-length character variables.
See also
Apr 24, 2016
Here's another example using the C interoperability features of modern Fortran. First introduced in Fortran 2003, this allows for easily calling C routines from Fortran (and vice versa) in a standard and portable way. Further interoperability features will also be added in the next edition of the standard.
For a Fortran user, strings in C are pretty awful (like most things in C). This example shows how to call a C function that returns a string (in this case, the dlerror function).
module get_error_module
use, intrinsic :: iso_c_binding
implicit none
private
public :: get_error
interface
!interfaces to C functions
function dlerror() result(error) &
bind(C, name='dlerror')
import
type(c_ptr) :: error
end function dlerror
function strlen(str) result(isize) &
bind(C, name='strlen')
import
type(c_ptr),value :: str
integer(c_int) :: isize
end function strlen
end interface
contains
function get_error() result(error_message)
!! wrapper to C function char *dlerror(void);
character(len=:),allocatable :: error_message
type(c_ptr) :: cstr
integer(c_int) :: n
cstr = dlerror() ! pointer to C string
if (c_associated(cstr)) then
n = strlen(cstr) ! get string length
block
!convert the C string to a Fortran string
character(kind=c_char,len=n+1),pointer :: s
call c_f_pointer(cptr=cstr,fptr=s)
error_message = s(1:n)
nullify(s)
end block
else
error_message = ''
end if
end function get_error
end module get_error_module
First we define the bindings to two C routines so that we can call them from Fortran. This is done using the INTERFACE block. The main one is the dlerror function itself, and we will also use the C strlen function for getting the length of a C string. The bind(C) attribute indicates that they are C functions. The get_error function first calls dlerror, which returns a variable of type(c_ptr), which is a C pointer. We use c_f_pointer to cast the C pointer into a Fortran character string (a CHARACTER pointer variable with the same length). Note that, after we know the string length, the block construct allows us to declare a new variable s of the length we need (this is a Fortran 2008 feature). Then we can use it like any other Fortran string (in this case, we assign it to error_message, the deferred-length string returned by the function).
Of course, Fortran strings are way easier to deal with, especially deferred-length (allocatable) strings, and don't require screwing around with pointers or '\0' characters. A few examples are given below:
subroutine string_examples()
implicit none
!declare some strings:
character(len=:),allocatable :: s1,s2
!string assignment:
s1 = 'hello world' !set the string value
s2 = s1 !set one string equal to another
!string slice:
s1 = s1(1:5) !now, s1 is 'hello'
!string concatenation:
s2 = s1//' '//s1 ! now, s2 is 'hello hello'
!string length:
write(*,*) len(s2) ! print length of s2 (which is now 11)
!and there are no memory leaks,
!since the allocatables are automatically
!deallocated when they go out of scope.
end subroutine string_examples
See also
Apr 09, 2016
Built-in high-level support for arrays (vectors and matrices) using a very clean syntax is one of the areas where Fortran really shines as a programming language for engineering and scientific simulations. As an example, consider matrix multiplication. Say we have an M x K matrix A, a K x N matrix B, and we want to multiply them to get the M x N matrix AB. Here's the code to do this in Fortran:
Now, here's how to do the same thing in C or C++ (without resorting to library calls) [1]:
for (int i = 0; i < M; i++) {
for (int j = 0; j < N; j++) {
AB[i][j]=0;
for (int k = 0; k < K; k++) {
AB[i][j] += A[i][k] * B[k][j];
}
}
}
MATMUL is, of course, Fortran's built-in matrix multiplication function. It was added to the language as part of the Fortran 90/95 standards which dramatically upgraded the language's array-handling facilities. Later standards also added additional array features, and Fortran currently contains a wide range of intrinsic array functions:
| Routine |
Description |
| ALL |
True if all values are true |
| ALLOCATED |
Array allocation status |
| ANY |
True if any value is true |
| COUNT |
Number of true elements in an array |
| CSHIFT |
Circular shift |
| DOT_PRODUCT |
Dot product of two rank-one arrays |
| EOSHIFT |
End-off shift |
| FINDLOC |
Location of a specified value |
| IPARITY |
Exclusive or of array elements |
| IS_CONTIGUOUS |
Test contiguity of an array |
| LBOUND |
Lower dimension bounds of an array |
| MATMUL |
Matrix multiplication |
| MAXLOC |
Location of a maximum value in an array |
| MAXVAL |
Maximum value in an array |
| MERGE |
Merge under mask |
| MINLOC |
Location of a minimum value in an array |
| MINVAL |
Minimum value in an array |
| NORM2 |
L2 norm of an array |
| PACK |
Pack an array into an array of rank one under a mask |
| PARITY |
True if number of elements in odd |
| PRODUCT |
Product of array elements |
| RESHAPE |
Reshape an array |
| SHAPE |
Shape of an array or scalar |
| SIZE |
Total number of elements in an array |
| SPREAD |
Replicates array by adding a dimension |
| SUM |
Sum of array elements |
| TRANSPOSE |
Transpose of an array of rank two |
| UBOUND |
Upper dimension bounds of an array |
| UNPACK |
Unpack an array of rank one into an array under a mask |
As an example, here is how to sum all the positive values in a matrix:
In addition to the array-handling functions, we can also use various other language features to make it easier to work with arrays. For example, say we wanted to convert all the negative elements of a matrix to zero:
Or, say we want to compute the dot product of the 1st and 3rd columns of a matrix:
d = dot_product(A(:,1),A(:,3))
Or, replace every element of a matrix with its sin():
That last one is an example of an intrinsic ELEMENTAL function, which is one that can operate on scalars or arrays of any rank. The assignment is done for each element of the array (and can potentially be vectored by the compiler). We can create our own ELEMENTAL functions like so:
elemental function cubic(a,b,c) result(d)
real(wp),intent(in) :: a,b,c
real(wp) :: d
d = a + b**2 + c**3
end function cubic
Note that the inputs and output of this function are scalars. However, since it is ELEMENTAL, it can also be used for arrays like so:
real(wp) :: aa,bb,cc,dd
real(wp),dimension(10,10,10) :: a,b,c,d
!...
dd = cubic(aa,bb,cc) ! works on these
d = cubic(a,b,c) ! also works on these
The array-handling features of Fortran make scientific and engineering programming simpler and less error prone, since the code can be closer to the mathematical expressions, as well as making vectorization by the compiler easier [2]. Here is an example from the Fortran Astrodynamics Toolkit, a vector projection function:
pure function vector_projection(a,b) result(c)
implicit none
real(wp),dimension(:),intent(in) :: a
!! the original vector
real(wp),dimension(size(a)),intent(in) :: b
!! the vector to project on to
real(wp),dimension(size(a)) :: c
!! the projection of a onto b
if (all(a==0.0_wp)) then
c = 0.0_wp
else
c = a * dot_product(a,b) / dot_product(a,a)
end if
end function vector_projection
Line 15 is the vector projection formula, written very close to the mathematical notation. The function also works for any size vector. A similar function in C++ would be something like this:
inline std::array<double,3>
vector_projection(const std::array<double,3>& a,
const std::array<double,3>& b)
{
if (a[0]==0.0 & a[1]==0.0 & a[2]==0.0){
std::array<double,3> p = {0.0, 0.0, 0.0};
return p;
}
else{
double aa = a[0]*a[0]+a[1]*a[1]+a[2]*a[2];
double ab = a[0]*b[0]+a[1]*b[1]+a[2]*b[2];
double abaa = ab / aa;
std::array<double,3>
p = {a[0]*abaa,a[1]*abaa,a[2]*abaa};
return p;
}
}
Of course, like anything, there are many other ways to do this in C++ (I'm using C++11 standard library arrays just for fun). Note that the above function only works for vectors with 3 elements. It's left as an exercise for the reader to write one that works for any size vectors like the Fortran one (full disclosure: I mainly just Stack Overflow my way through writing C++ code!) C++'s version of dot_product seems to have a lot more inputs for you to figure out though:
double ab = std::inner_product(a.begin(),a.end(),b.begin(),0.0);
In any event, any sane person using C++ for scientific and engineering work should be using a third-party array library, of which there are many (e.g., Boost, EIGEN, Armadillo, Blitz++), rather than rolling your own like we do at NASA.
References
- Walkthrough: Matrix Multiplication [MSDN]
- M. Metcalf, The Seven Ages of Fortran, Journal of Computer Science and Technology, Vol. 11 No. 1, April 2011.
- My Corner of the World: C++ vs Fortran, September 07, 2011
Apr 05, 2016

This newfangled Atom hipster text editor is really a nice editor for Fortran when you install these two plugins:
There are tons of other packages too. For example, indent-helper is a must, because every sane person knows that ='s and ::'s should always be aligned.
For many years, I've used TextWrangler by Bare Bones Software (which is the free version of their more powerful BBEdit). Just having the Fortran linter (see below) is enough to make me switch. I suppose with the right combination of plugins, I could use it as a full-fledged IDE, but I haven't really tried to do that yet.
Maybe one day @szaghi will write a FoBiS plugin for Atom. Unfortunately, I think he's totally committed to vi.
See also
Apr 05, 2016
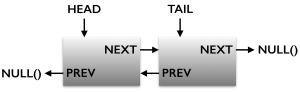
So, I want to have a basic linked list manager, written in modern Fortran (2003/2008). Of course, Fortran provides you with nothing like this out of the box, but it does provide the tools to create such a thing (within reason). Pointers (introduced in Fortran 90) allow for the creation of dynamic structures such as linked lists. In Fortran, you can do quite a lot without having to resort to pointers (say, compared to C, where you can't get away from them if you want to do anything nontrivial), but in this case, we need to use them. With the addition of unlimited polymorphic variables in Fortran 2003, we can now also create heterogeneous lists containing different types of variables, which is quite handy. There are some good Fortran linked-list implementations out there (see references below). But none seemed to do exactly what I wanted. Plus I wanted to learn about this stuff myself, so I went ahead and started from scratch. My requirements are that the code:
- Accept any data type from the caller. I don't want to force the caller to stuff their data into some standard form, or make them have to extend an abstract derived type to contain it.
- Accept data that may perhaps contain targets of pointers from other variables that are not in the list. This seems useful to me, but is an aspect that is missing from the implementations I have seen, as far as I can tell. If the data is being pointed to by something externally, doing a sourced allocation to create a copy is not acceptable, since the pointers will still be pointing to the original one and not the copy.
- Allow for the list to manage the destruction of the variable (deallocation of the pointer, finalization if it is present), or let the user handle it. Perhaps the list is being used to collocate and access some data, but if the list goes out of scope, the data is intended to remain.
- In general, limit the copying of data (some entries in the list may be very large and it is undesirable to make copies).
- Allow the key to be an integer or string (or maybe other variable types as well)
For lack of a better name, I've called the resultant library FLIST (it's on GitHub). It's really just an experiment at this point, but I think it does everything I need. The node data type used to construct the linked list is this:
type :: node
private
class(*),allocatable :: key
class(*),pointer :: value => null()
logical :: destroy_on_delete = .true.
type(node),pointer :: next => null()
type(node),pointer :: previous => null()
contains
private
procedure :: destroy => destroy_node_data
end type node
The data in the node is a CLASS(*),POINTER variable (i.e, a pointer to an unlimited polymorphic variable). This will be associated to the data that is added to the list. Data can be added as a pointer (in which case no copying is performed), or added as a clone (where a new instance of the node data is instantiated and a copy of the input data is made). If the data is added as a pointer, the user can also optionally specify if the data is to be destroyed when the list is destroyed or goes out of scope (or if the item is deleted from the list).
The key is also an unlimited polymorphic variable (in the user-accessible API, keys are limited to integers, character strings, or extensions of an abstract key_class):
type,abstract,public :: key_class
contains
procedure(key_equal_func),deferred :: key_equal
generic :: operator(==) => key_equal
end type key_class
The key types have to be limited, since there has to be a way to check for equality among keys (the abstract key_class has a deferred == operator that must be specified). The Fortran SELECT TYPE construct is used to resolve the polymorphic variables in order to check for equality among keys.
A simple example use case is shown below. Here we have some derived type gravity_model that is potentially very large, and is initialized by reading a data file. The subroutine takes as input a character array of file names to read, loads them, and appends the resultant models to the list_of_models.
subroutine add_some_models(files,list_of_models)
use linked_list_module
use gravity_model_module
implicit none
character(len=:),dimension(:),intent(in) :: files
type(list),intent(inout) :: list_of_models
integer :: i
type(gravity_model),pointer :: g
do i=1,size(files)
allocate(g)
call g%initialize(files(i))
call list_of_models%add_pointer(files(i),g)
nullify(g)
end do
end subroutine add_some_models
In this example, all the models are allocated in the subroutine, and then added as pointers to the list (the file name is used as the key). When list_of_models goes out of scope, the models will be deallocated (and finalized if gravity_model contains a finalizer). A model can be removed from the list (which will also trigger finalization) using the key, like so:
call list_of_models%remove('blah.dat')
More complex use cases are also possible (see the code for more details). As usual, the license is BSD, so if anybody else finds it useful, let me know.
See also
- T. Dunn, fortran-linked-list [GitHub]
- T. Degawa, LinkedList [GitHub]
- libAtoms/QUIP [GitHub]
- N. R. Papior, fdict [GitHub]
- C. MacMackin, FIAT [GitHub]
- J. R. Blevins, A Generic Linked List Implementation in Fortran 95, ACM Fortran Forum 28(3), 2–7, 2009.
Apr 03, 2016
Here is some C++ code (from actual NASA software):
aTilde[ 0] = aTilde[ 1] = aTilde[ 2] =
aTilde[ 3] = aTilde[ 4] = aTilde[ 5] =
aTilde[ 6] = aTilde[ 7] = aTilde[ 8] =
aTilde[ 9] = aTilde[10] = aTilde[11] =
aTilde[12] = aTilde[13] = aTilde[14] =
aTilde[15] = aTilde[16] = aTilde[17] =
aTilde[18] = aTilde[19] = aTilde[20] =
aTilde[21] = aTilde[22] = aTilde[23] =
aTilde[24] = aTilde[25] = aTilde[26] =
aTilde[27] = aTilde[28] = aTilde[29] =
aTilde[30] = aTilde[31] = aTilde[32] =
aTilde[33] = aTilde[34] = aTilde[35] = 0.0;
Here is the same code translated to Fortran:
😀
References
Mar 14, 2016
Fortran namelists are a quick and dirty way of reading and writing variables to and from a file. It is actually the only high-level file access feature built into the Fortran language, in the sense of being able to read and write a complex formatted file with one line of code. Nowadays, I would recommend against using this feature since the format is not really a standard and varies from compiler to compiler, and there aren't good parsers available for other languages (with the notable exception of Python). There are better configuration file formats available today such as JSON. However, namelists can still be encountered in legacy applications, and may still be useful to the lazy programmer.
One of the problems with namelists is that all the variables in the file have to correspond exactly in name, type, rank, and size to variables declared in your code. Syntax errors in the file are not easily detected and a failed read due to an unexpected variable will usually just return a non-zero status code that isn't really much help in diagnosing the problem.
However, there is a way to output the line where the failure occurred on a namelist read, which can be quite useful for debugging. Say your code is expecting a namelist containing three real variables a, b, and c. However, the file contains the unexpected variable d like so:
&my_namelist
a = 1.0,
b = 2.0,
d = 3.0,
c = 4.0
/
Now consider the following Fortran code to read it:
program namelist_test
use iso_fortran_env, wp => real64
implicit none
real(wp) :: a,b,c ! namelist variables
integer :: istat,iunit
character(len=1000) :: line
namelist /my_namelist/ a,b,c
open(newunit=iunit,file='my_namelist.nml',&
status='OLD')
read(iunit, nml=my_namelist, iostat=istat)
if (istat/=0) then
backspace(iunit)
read(iunit,fmt='(A)') line
write(error_unit,'(A)') &
'Invalid line in namelist: '//trim(line)
end if
close(iunit)
end program namelist_test
The READ statement will fail with a non-zero istat code. Then we simply use the BACKSPACE function, which moves the file position back one record (the record where the read failed). Then we can simply read this line and print it. This code produces the following error message:
Invalid line in namelist: d = 3.0,
{kind=link}