Fortran90.org has a nice page showing side-by-side comparisons of the same code in both NumPy and Fortran. Aside from a few weird quirks (see the array slice examples), Python code should be easily understandable by a Fortran programmer.
Fortran 2003 was a significant update to Fortran 95 (probably something on the order of the update from C to C++). It brought Fortran into the modern computing world with the addition of object oriented programming features such as type extension and inheritance, polymorphism, dynamic type allocation, and type-bound procedures.
The following example shows an implementation of an object oriented class to perform numerical integration of a user-defined function using a Runge-Kutta method (in this case RK4). First, an abstract rk_class is defined, which is then extended to create the RK4 class by associating the deferred step method to rk4. Other RK classes could also be created in a similar manner. In order to use the class, it is only necessary to set n (the number of variables in the state vector) and f (the user-supplied derivative function), and then call the integrate method.
module rk_module
use, intrinsic :: iso_fortran_env, wp => real64 !double precision reals
implicit none
real(wp),parameter :: zero = 0.0_wp
!main integration class:
type,abstract,public :: rk_class
private
!user specified number of variables:
integer :: n = 0
!user-specified derivative function:
procedure(deriv_func),pointer :: f => null()
contains
procedure,non_overridable,public :: integrate !main integration routine
procedure(step_func),deferred :: step !the step routine for the selected method
end type rk_class
!extend the abstract class to create an RK4 method:
! [all we need to do is set the step function]
type,extends(rk_class),public :: rk4_class
contains
procedure :: step => rk4
end type rk4_class
interface
subroutine deriv_func(me,t,x,xdot) !derivative function
import :: rk_class,wp
implicit none
class(rk_class),intent(inout) :: me
real(wp),intent(in) :: t
real(wp),dimension(me%n),intent(in) :: x
real(wp),dimension(me%n),intent(out) :: xdot
end subroutine deriv_func
subroutine step_func(me,t,x,h,xf) !rk step function
import :: rk_class,wp
implicit none
class(rk_class),intent(inout) :: me
real(wp),intent(in) :: t
real(wp),dimension(me%n),intent(in) :: x
real(wp),intent(in) :: h
real(wp),dimension(me%n),intent(out) :: xf
end subroutine step_func
end interface
contains
subroutine integrate(me,t0,x0,h,tf,xf)
! main integration routine
implicit none
class(rk_class),intent(inout) :: me
real(wp),intent(in) :: t0
real(wp),dimension(me%n),intent(in) :: x0
real(wp),intent(in) :: h
real(wp),intent(in) :: tf
real(wp),dimension(me%n),intent(out) :: xf
real(wp) :: t,dt,t2
real(wp),dimension(me%n) :: x
logical :: last
if (h==zero) then
xf = x0
else
t = t0
x = x0
dt = h
do
t2 = t + dt
last = ((dt>=zero .and. t2>=tf) .or. & !adjust last time step
(dt<zero .and. t2<=tf)) !
if (last) dt = tf-t !
call me%step(t,x,dt,xf)
if (last) exit
x = xf
t = t2
end do
end if
end subroutine integrate
subroutine rk4(me,t,x,h,xf)
! Take one Runge Kutta 4 integration step: t -> t+h (x -> xf)
implicit none
class(rk4_class),intent(inout) :: me
real(wp),intent(in) :: t
real(wp),dimension(me%n),intent(in) :: x
real(wp),intent(in) :: h
real(wp),dimension(me%n),intent(out) :: xf
!local variables:
real(wp),dimension(me%n) :: f1,f2,f3,f4
real(wp) :: h2
!parameters:
real(wp),parameter :: half = 0.5_wp
real(wp),parameter :: six = 6.0_wp
h2 = half*h
call me%f(t,x,f1)
call me%f(t+h2,x+h2*f1,f2)
call me%f(t+h2,x+h2*f2,f3)
call me%f(t+h,x+h*f3,f4)
xf = x + h*(f1+f2+f2+f3+f3+f4)/six
end subroutine rk4
end module rk_module
An example use of this module follows. Here, we are integrating the equations of motion of a spacecraft in Earth orbit, using two-body assumptions: \(\ddot{\mathbf{r}} = -\frac{\mu}{r^3}\mathbf{r}\)
The rk4_class is extended to create a new spacecraft class, which contains the data required by the derivative routine (in this case, simply the central body gravitational parameter mu). A more complicated version could also include spherical harmonic gravity, solar radiation pressure, atmospheric drag, engine thrust, etc. Note that the select type statement is necessary in the derivative routine in order to access the data from the extended type.
program main
use rk_module
!spacecraft propagation type:
! extend the rk class to include data used in the deriv routine
type,extends(rk4_class) :: spacecraft
real(wp) :: mu = zero ! central body gravitational
! parameter (km^3/s^2)
end type spacecraft
integer,parameter :: n=6 !number of state variables
type(spacecraft) :: s
real(wp) :: t0,tf,x0(n),dt,xf(n)
!constructor:
s = spacecraft(n=n,f=twobody,mu=398600.436233_wp) !main body is Earth
!initial conditions:
x0 = [10000.0_wp,10000.0_wp,10000.0_wp,& !initial state [x,y,z] (km)
1.0_wp,2.0_wp,3.0_wp] ! [vx,vy,yz] (km/s)
t0 = zero !initial time (sec)
dt = 10.0_wp !time step (sec)
tf = 1000.0_wp !final time (sec)
call s%integrate(t0,x0,dt,tf,xf)
write(*,'(A/,*(F15.6/))') 'Final state:',xf
contains
subroutine twobody(me,t,x,xdot)
! derivative routine for two-body orbit propagation
implicit none
class(rk_class),intent(inout) :: me
real(wp),intent(in) :: t
real(wp),dimension(me%n),intent(in) :: x
real(wp),dimension(me%n),intent(out) :: xdot
real(wp),dimension(3) :: r,v,a_grav
real(wp) :: rmag
select type (me)
class is (spacecraft)
r = x(1:3)
v = x(4:6)
rmag = norm2(r)
a_grav = -me%mu/rmag**3 * r !accel. due to gravity
xdot(1:3) = v
xdot(4:6) = a_grav
end select
end subroutine twobody
end program main
The result is:
Final state: 10667.963305 11658.055962 12648.148619 0.377639 1.350074 2.322509
See also
- Object-Oriented Programming in Fortran 2003 Part 1: Code Reusability, PGI Insider, Feb. 2011.
- Object-Oriented Programming in Fortran 2003 Part 2: Data Polymorphism, PGI Insider, June 2011.
- Fortran Astrodynamics Toolkit (Github)
Intel has released version 15 of their Fortran compiler (the product formerly known as Intel Visual Fortran, and now part of the confusingly-named "Intel Parallel Studio XE 2015 Composer Edition", is an update to the v14 release which was called "Intel Composer XE 2013 SP1"). The big news is that it now includes full support for the Fortran 2003 standard. This release also adds support for the BLOCK construct and EXECUTE_COMMAND_LINE intrinsic subroutine from Fortran 2008.
See also
- Compiler support for the Fortran 2003 Standard

The Computus is the algorithm for the calculation of the date of Easter. The following is a simple Fortran subroutine of the Computus, using the "Meeus/Jones/Butcher" Gregorian Easter algorithm. Note that this subroutine makes use of Fortran integer division.
subroutine easter(year,month,day)
!Compute the date of Gregorian Easter,
! using the "Meeus/Jones/Butcher" algorithm
implicit none
integer,intent(in) :: year
integer,intent(out) :: month,day
integer :: a,b,c,d,e,f,g,h,i,k,l,m
a = mod(year,19)
b = year/100
c = mod(year,100)
d = b/4
e = mod(b,4)
f = (b+8)/25
g = (b-f+1)/3
h = mod((19*a+b-d-g+15),30)
i = c/4
k = mod(c,4)
l = mod((32+2*e+2*i-h-k),7)
m = (a+11*h+22*l)/451
month = (h+l-7*m+114)/31
day = mod(h+l-7*m+114,31)+1
end subroutine easter
The sequence of dates repeat themselves over a cycle of 5,700,000 years. The following histogram shows the percentage occurrence of each date (from March 22nd to April 25th), over the entire cycle:
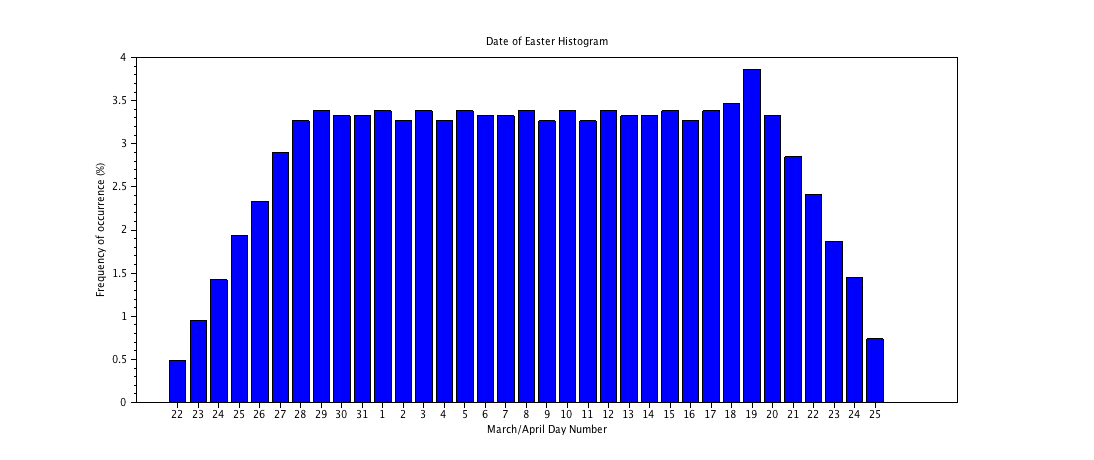
See also
- D. Steel, "Marking Time: The Epic Quest to Invent the Perfect Calendar", Wiley, 1999.
- J. R. Stockton, "The Calculation of Easter Sunday after the Book of Common Prayer of the Church of England".
Old style fixed-form Fortran code (commonly called FORTRAN 77 style) was replaced by free-form style in 1991 with the introduction of the Fortran 90 standard. In spite of this, fixed-form code can still be found in legacy projects, and there are some people who still write it for whatever reason (possibly unaware that a better format exists). There are also a large number of high-quality legacy fixed-form code libraries from back in the day that still work great. All modern Fortran compilers accept both fixed and free-form code, but there is very little reason for new fixed-form code to be written today. Also, it is often convenient to convert old-style code to free-format if it is going to be maintained or upgraded by a programmer in the present day. The following list provides links to several free tools to convert fixed-form code to free-form code (there are also several commercially-available solutions):
See also
- Source Form Just Wants to be Free
- Modernizing Old Fortran
Yes, now animated GIFs can be created using only Fortran code. I present FGIF, now on GitHub. It is a modified and updated version of the public domain code found on the Fortran Wiki. It was used to create the image shown here (which is an example of a circle illusion).
For more information on the GIF format, see:
It was interesting to discover that animated GIFs are actually a Netscape extension to the GIF file format. If you open any animated GIF in a hex editor, you will find the string "NETSCAPE2.0".
JPL just released a new version of the SPICE Toolkit (N65). According to the What's New page, changes include:
- support for some new environments and termination of some old environments
- new Geometry Finder (GF) interfaces -- illumination angle search, phase angle search, user-defined binary quantity search
- new high-level SPK APIs allowing one to specify the observer or target as a location with a constant position and velocity rather than as an ephemeris object
- new high-level APIs that check for occultation and in-Field-Of-View (FOV) conditions
- new high-level illumination angle routines
- new high-level reference frame transformation routine
- new high-level coordinate system transformation routine for states
- many Icy and Mice APIs that were formerly available only in SPICELIB and CSPICE
- new data types: SPK (19, 20, 21), PCK (20), and CK (6)
- performance improvements in the range of 10-50 percent for some types of use
- ability to load up to 5000 kernels
- increased buffers in the POOL and in SPK and CK segment search subsystems
- new built-in body name/ID code mappings and body-fixed reference frames
- a significant upgrade of utility SPKDIFF including the ability to sample SPK data
- updates to other toolkit utilities -- BRIEF, CKBRIEF, FRMDIFF, MKSPK, MSOPCK
- bug fixes in Toolkit and utility programs
Rodrigues' rotation formula can be used to rotate a vector \(\mathbf{v}\) a specified angle \(\theta\) about a specified rotation axis \(\mathbf{k}\):
$$
\mathbf{v}_\mathrm{rot} = \mathbf{v} \cos\theta + (\hat{\mathbf{k}} \times \mathbf{v})\sin\theta
+ \hat{\mathbf{k}} (\hat{\mathbf{k}} \cdot \mathbf{v}) (1 - \cos\theta)
$$
A Fortran routine to accomplish this (taken from the vector module in the Fortran Astrodynamics Toolkit) is:
subroutine rodrigues_rotation(v,k,theta,vrot)
implicit none
real(wp),dimension(3),intent(in) :: v !vector to rotate
real(wp),dimension(3),intent(in) :: k !rotation axis
real(wp),intent(in) :: theta !rotation angle [rad]
real(wp),dimension(3),intent(out) :: vrot !result
real(wp),dimension(3) :: khat
real(wp) :: ct,st
ct = cos(theta)
st = sin(theta)
khat = unit(k)
vrot = v*ct + cross(khat,v)*st + &
khat*dot_product(khat,v)*(one-ct)
end subroutine rodrigues_rotation
This operation can also be converted into a rotation matrix, using the equation:
$$
\mathbf{R} = \mathbf{I} + [\hat{\mathbf{k}}\times]\sin \theta + [\hat{\mathbf{k}}\times] [\hat{\mathbf{k}}\times](1-\cos \theta)$$
Where the matrix \([\hat{\mathbf{k}}\times]\) is the skew-symmetric cross-product matrix and \(\mathbf{v}_\mathrm{rot} = \mathbf{R} \mathbf{v}\).
References
- Rotation Formula [Mathworld]
- Rodrigues' Rotation Formula [Mathworld]
- Do We Really Need Quaternions? [Gamedev.net]
- R. T. Savely, B. F. Cockrell, and S. Pines, "Apollo Experience Report -- Onboard Navigational and Alignment Software", NASA TN D-6741, March 1972. See the Appendix by P. F. Flanagan and S. Pines, "An Efficient Method for Cartesian Coordinate Transformations".
